
前段时间看到一个视频,说 Dubbo 代码中有个地方明明可以直接用 switch 判断,但是代码里用了 if + switch,因为 if 走分支预测可以加速执行,而 switch 需要先查一个地址表。让我想起了这篇没有翻译完成的文章…
原文地址:https://blog.cloudflare.com/branch-predictor/
原文标题:Branch predictor: How many “if”s are too many? Including x86 and M1 benchmarks!
原文作者:Marek Majkowski
原文写于:2021/05/06
译者:驱蚊器喵#ΦωΦ
翻译水平有限,有不通顺的语句,请见谅。
前阵子,我在我们代码的热点部分,看见这样一段代码:
1 | if (debug) { |
这让我陷入深思。这段代码是在一个性能关键的循环中,看起来是一种浪费 - 而且我们从来没有在启用 “调试(debug)” 标志的情况下运行程序[^1]。有一些基本上不会被运行的if条件,这没有问题吗?当然,这肯定会有一些性能上的代价…
在代码中加入本可避免的if语句到底有多糟?
过去的经验告诉我们:如果分支是“完全可预测”的,它几乎不会消耗 CPU 资源。
那么这条经验有多可靠?如果一个分支没问题,那么十个呢?一百个呢?一千个呢?究竟什么时候,添加更多的 if 就会成为性能杀手?
在某些时候,简单的分支指令本可忽略的消耗肯定会增加到一个重要的数额。另一个例子,一个同事在我们的生产代码中发现了这个片段:
1 | const char *getCountry(int cc) { |
很明显,这段代码可以改进[^2]。但是,当我更多地考虑到:它应该被改进吗?由一系列简单分支组成的代码,是否有实际的性能冲击?
了解跳转的代价
在开始我们的旅程之前,我们必须要讲一些理论知识。我们想弄清楚,当我们增加更多的分支时,分支的 CPU 计算成本是否会增加。事实证明,评估分支的开销并非容易的事情。在现代处理器上,一个分支指令可能需要 1 到 20 个 CPU 周期。控制流指令至少有四类[^3]:无条件分支( x86 上的 jmp )、调用/返回(call/return)、已执行的条件分支(例如 x86 上的 je )并执行、条件分支但未执行。已执行的分支特别有问题:如果不特别注意,它们本身就有很大的成本 - 我们将在下一节解释。为了降低成本,现代 CPU 试图预测未来,并在分支实际完全执行之前找出分支的目标!这是在处理器的一个被称为 分支预测器单元(BPU, branch predictor unit)的部分中完成的。
分支预测器试图在很早的时候就弄清分支指令的目标,而且是在少量上下文的情况下。这个魔术发生在 “解码器” 流水线阶段之前,预测器的可用数据非常有限。它只有一些过去的历史和当前指令的地址。如果你想一想–这真是超级强大。仅凭当前的指令指针,它就可以非常有把握地评估跳转的目标位置。
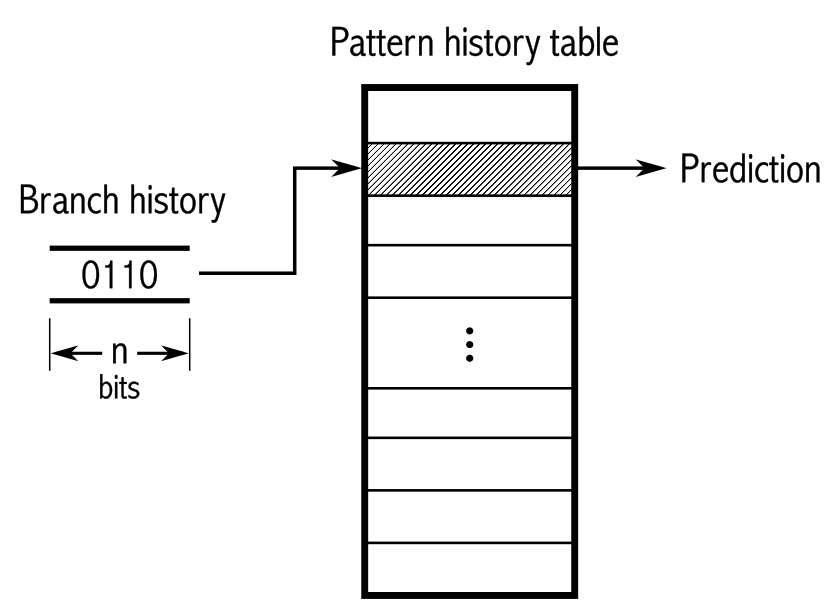
来源: https://en.wikipedia.org/wiki/Branch_predictor
BPU 维护着一些数据结构,但今天我们将关注分支目标缓冲区(BTB,Branch Target Buffer)。它是 BPU 记忆以前执行分支的目标指令指针的地方。整个机制要复杂得多,请看 Vladimir Uzelac 的硕士论文,了解 2008 年以来 CPU 上分支预测的细节。
在本文的范围内,我们将简化并只关注 BTB。我们将尝试展示它有多大,以及它在不同条件下的表现如何。
为什么需要分支预测?
但首先,为什么要使用分支预测?为了获得最佳性能,CPU 流水线必须提供稳定的指令流。考虑一下,多级 CPU 流水线在一个分支指令上会发生什么。为了说明这一点,让我们考虑下面的 ARM 程序。
1 | BR label_a; |
(译者注:这有点像 goto,BR 是 branch 的缩写,BR label_a; 代表程序执行时会跳转到 label_a 后的代码块执行,X1 到 label_a 之前的行将不会执行)
假设一个简单的 CPU 模型,这些操作会像这样在流水线上流动。
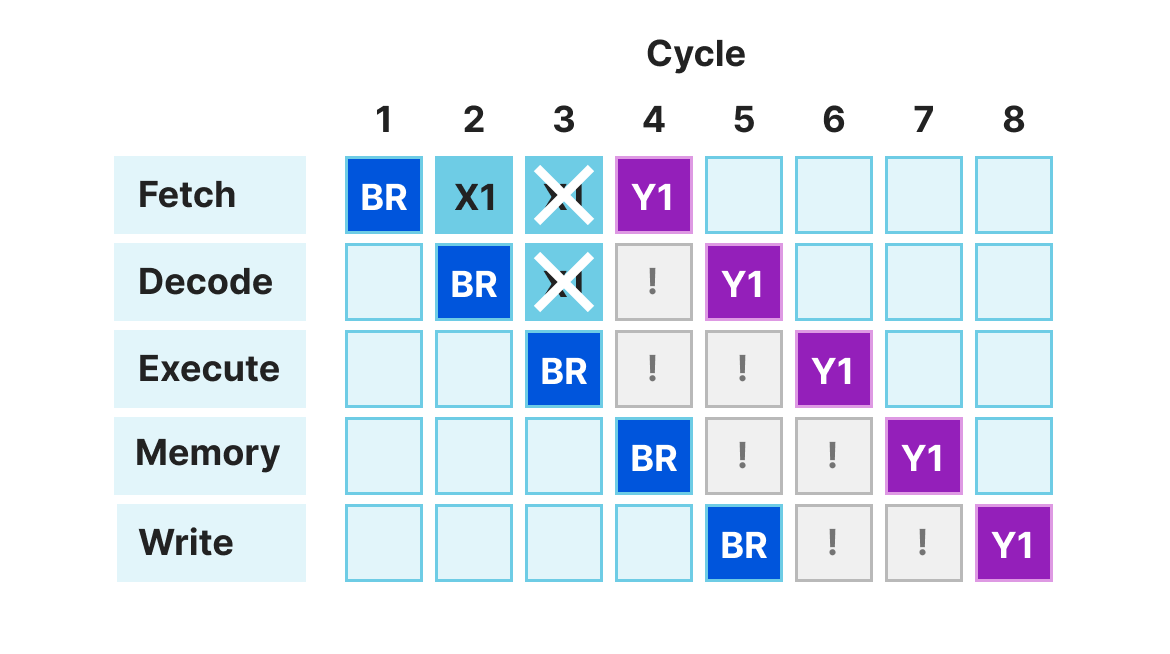
在第一个周期,BR 指令被获取。这是一个无条件的分支指令,改变了 CPU 的执行流程。此时,它还没有被解码,但 CPU 已经想获取另一条指令了! 如果在第 2 周期没有分支预测器,获取单元要么等待,要么就继续获取内存中的下一条指令,希望它是需要被执行的指令。
在我们的例子中,指令 X1 被获取到了,尽管这不是正确的指令。在周期 4 中,当分支指令完成执行阶段时,CPU 将能够理解这个错误,并在其产生任何影响之前回滚推测的指令。这时,取数单元被更新,以正确获得正确的指令–在我们的例子中是 Y1。
这种由于从错误的地方获取代码而损失若干周期的情况被称为 “前端泡沫(frontend bubble)”。当一个分支目标没有被正确预测时,我们的理论 CPU 有两个周期的前端泡沫。
在这个例子中,我们看到,尽管 CPU 最终做了正确的事情,但如果没有良好的分支预测,它就会在无需执行的指令上浪费精力。在过去,各种技术被用来减少这个问题,如静态分支预测和分支延迟槽。但是当前主流的 CPU 设计都是依靠动态分支预测。这种技术能够在很大程度上避免前端泡沫的问题,即使对于还没有完全解码和执行的分支,也能预测出下一条指令的正确地址。
使用 BTB
今天我们重点讨论 BTB - 一个由分支预测器管理的数据结构,负责找出分支的目标。值得注意的是,BTB 与评估分支是否被执行的系统是不同的,也是独立的。记住,我们要弄清楚当我们运行更多的分支时,分支的成本是否增加。
准备一个只压力测试 BTB 的实验是相对简单的(基于 Matt Godbolt 的工作)。事实证明,一连串的无条件 jmps 是完全足够的。看一下这个 X86 代码。
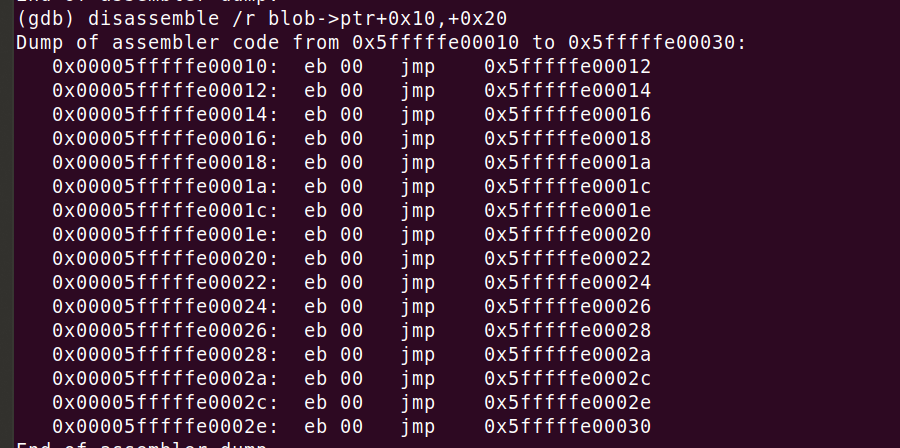
这段代码对 BTB 的压力达到了极致 - 它只是由一连串的 jmp +2 语句组成(也就是真正地跳到下一条指令)。为了避免在前端流水线泡沫上浪费周期,每次跳转都需要一个 BTB 命中。这种分支预测必须发生在 CPU 流水线的早期,在指令解码完成之前。任何分支都需要这种机制,无论它是无条件的、有条件的还是函数调用的。
上面的代码是在一个测试系统中运行的,该系统测量每条指令经过多少个 CPU 周期。例如,在这次运行中,我们正在测量密集的时间 - 每两个字节 - 1024条 jmp 指令一个接一个运行:
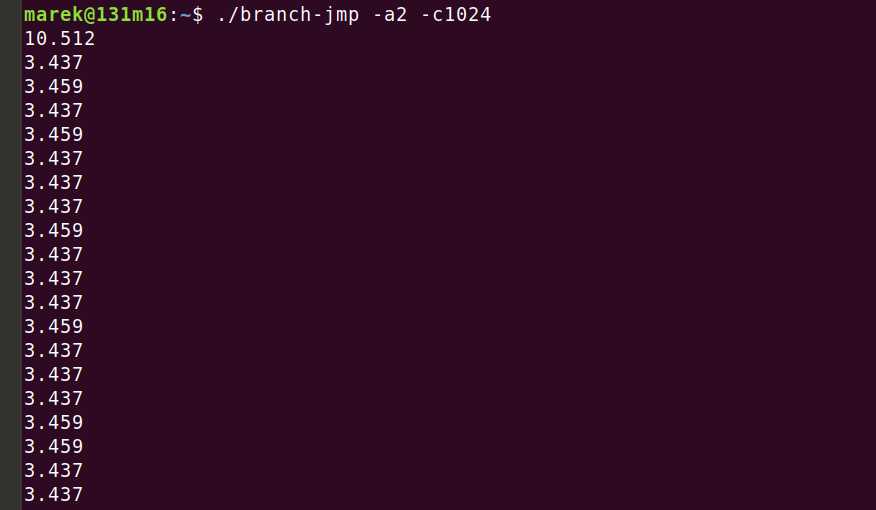
对于一些不同的 CPU,我们会看一下这样的实验结果。但在这个例子中,这是在一台装有 AMD EPYC 7642 的机器上运行的。在这里,冷运行每 jmp 需要 10.5 个周期,然后所有后续运行每 jmp 需要 ~3.5 个周期。这段代码是以这样的方式准备的,以确保是 BTB 减速了第一次运行。看一下完整的代码,有一些神奇的方法来预热 L1 缓存和 iTLB,而不需要 BTB 来辅助。
提示 1: 在这个 CPU 上,一条预测失败(被执行但未被预测)的分支指令比一条预测成功(被执行并被预测)的指令要多花费7个周期。 即使该分支是无条件的。
密度问题
为了全面了解情况,我们还需要考虑代码中 jmp 指令的密度。上面的代码在每个 16 字节的代码块中做了 8 个jmps。这是一个很大的数字。例如,下面的代码在每个 16 字节的代码块中包含 1 条jmp 指令。注意,nop 操作码是跳过的意思。代码块的大小并不改变执行指令的数量,只改变代码的密度。
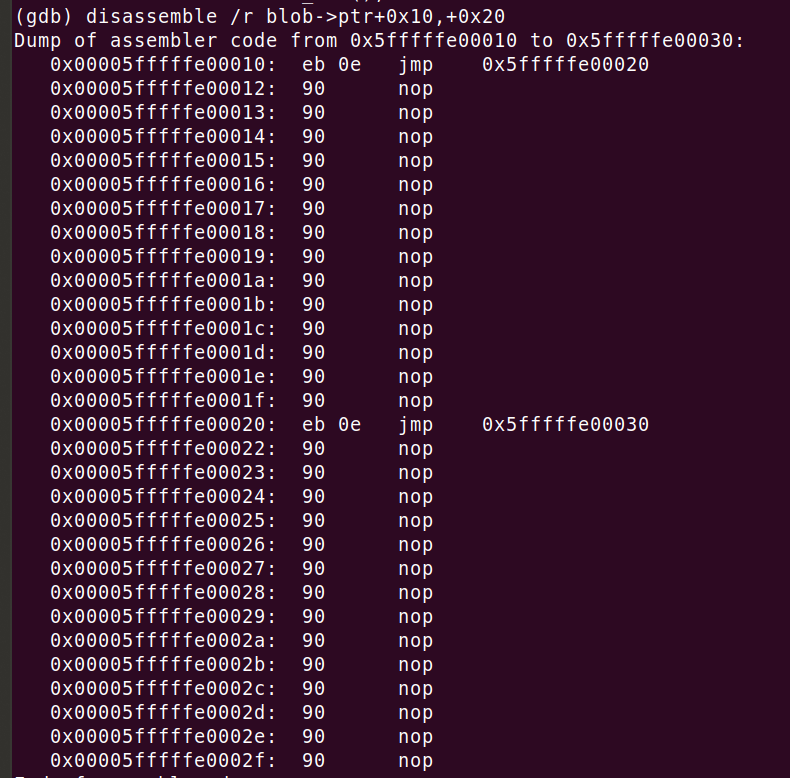
改变 jmp 块的大小可能是重要的。它允许我们控制 jmp 操作码的位置。记住,BTB 是由指令指针地址索引的。它的值和它的对齐方式可能会影响 BTB 中的位置,并帮助我们揭示 BTB 的布局。增加对齐方式将导致更多的 nop 填充物被添加。单个测量指令 - 本例中的 jmp - 和零个或多个nops 的序列,我将称之为 “块”,其大小为 “块大小”。请注意,块的大小越大,CPU 的工作代码大小就越大。在更大的数值下,我们可能会看到由于耗尽 L1 缓存空间而导致的一些性能下降。
实验
我们的实验是为了显示在不同的工作代码大小下,因为分支的数量导致的性能下降。希望我们能够证明性能主要取决于块的数量 - 也就是 BTB 大小,而不是工作代码大小。
请看 GitHub 上的代码。不过,如果你想看到生成的机器代码,你需要运行一个特殊的命令。它是由代码程序性地创建的,由传递的参数定制。这里有一个 gdb 咒语样例:

让我们把实验往前推进一步:如果我们在 BTB 已完全预热的情况下,取每次运行的最佳耗时,分别测试不同的 jmp 代码块大小 和 代码块数量(即工作集大小),会得到什么结果呢?请看:
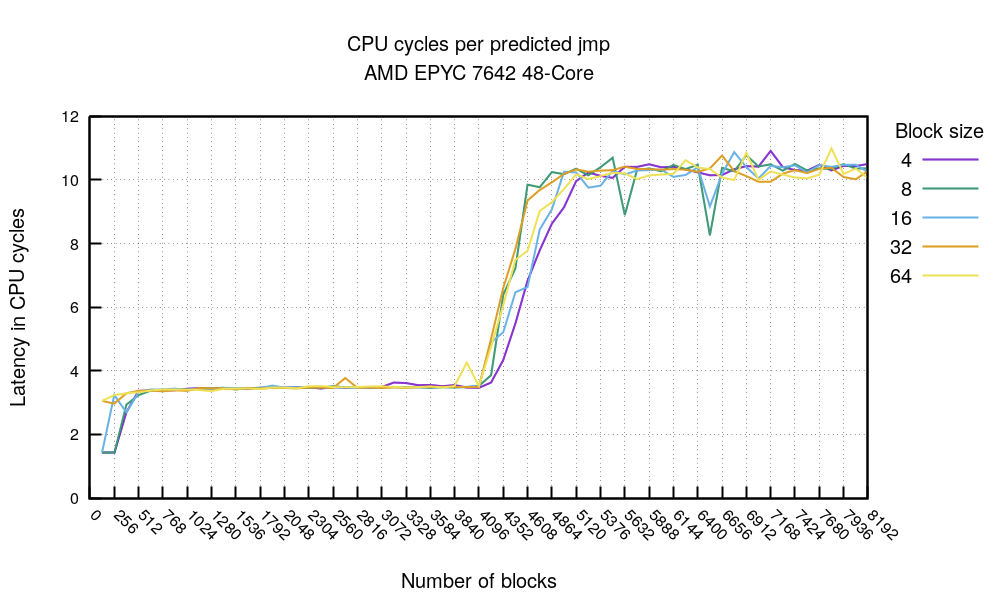
这是一个令人惊讶的图表。首先,不管 jmp 块的大小有多大 - 不管我们跳过了多少个 nop,在4096 个 jmp 标记[^4]处,那里显然发生一些事情。请大声读出来:
- 在最左边,我们看到,如果代码量足够小 - 小于 2048 字节(256 次 8 字节的块)- 就有可能命中某种 uop/L1 缓存,并在每个完全预测的分支上需要 ~1.5 周期。这是很惊人的。
- 否则,如果你将你的热循环保持在 4096 个分支,那么,无论你的代码多么密集,你都可能看到每个完全预测的分支需要 3.4 个周期。
- 超过 4096 个分支时,分支预测器就会放弃,每个分支的成本就会上升到每个 jmp ~10.5 周期。这与我们上面看到的一致 - 刷新的 BTB 在未预测的分支花费了 ~10.5 个周期。
很好,那么这意味着什么呢?好吧,如果你想避免分支失误,你应该避免分支指令,因为你最多有4096 个快速 BTB 槽。但这并不是一个非常实用的建议 - 我们不会故意在真实的代码中放很多无条件的 jmps!
对于讨论中的 CPU 来说,有几个启示。我用一个总是采取条件分支的序列重复了这个实验,结果图表看起来几乎是一样的。唯一的区别是预测执行的 条件-je 指令比无条件 jmp 慢了 2 个周期。
只要有分支被 “执行” - 也就是实际发生了跳转,就会在 BTB 中加入一个条目。一个无条件的 “jmp” 或一直执行的条件分支,将花费一个 BTB 槽。为了获得最佳性能,确保热循环中的分支不超过 4096 个。好消息是,从未执行的分支不会占用 BTB 的空间。我们可以用另一个实验来说明这一点。
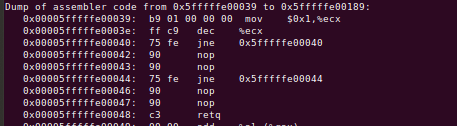
这段枯燥的代码是在未执行的 jne 之后再进行两个 nops(块大小=4)。针对这个测试(jne 从未执行),前一个测试(jmp 总是执行)和一个条件分支 je 总是执行,我们可以画出这个图表。
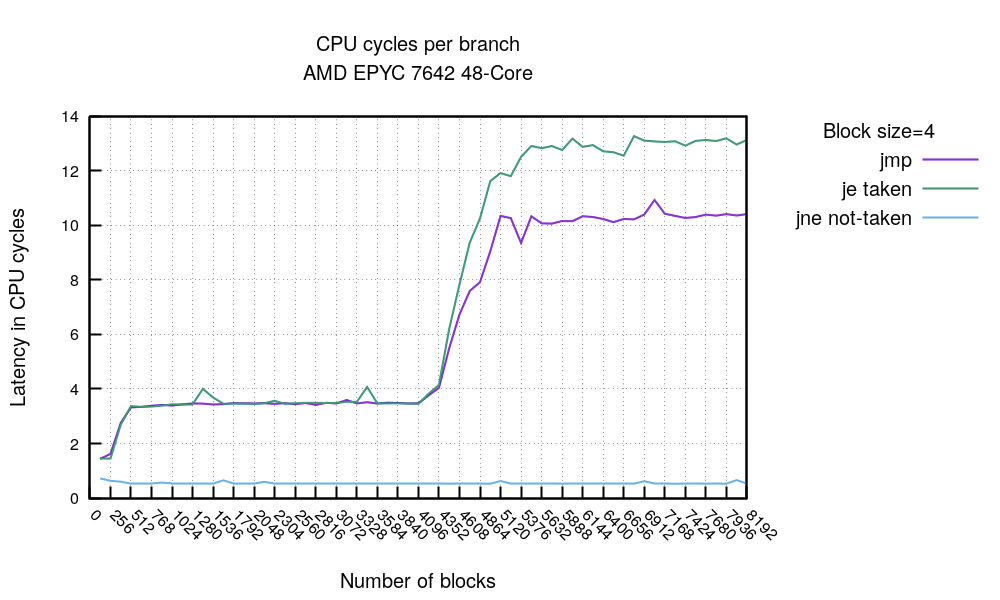
首先,不出意料,我们可以看到条件性的 “总是命中的 je 条件跳转” 比简单的无条件 jmp 的成本要高一些,但只是在 4096 个分支的标志之后。这很好理解,因为条件性分支在流水线中解析得较晚,所以前端的泡沫较长。然后看一下在零附近徘徊的蓝线。这是 “从未命中的 jne 条件跳转” 线,无论我们依次运行多少个块,持平于 0.3 个时钟/块。结论很清楚:你可以有尽可能多的从未被占用的分支,而不会产生任何成本。并且在 4096 次跳转 处没有任何尖峰,这意味着在这种情况下没有使用 BTB(分支目标缓冲,Branch Target Buffer)。看起来,之前未见过的条件跳转默认会被预测为 不跳转(not-taken)。
提示 2:那些条件分支如果始终不执行(never-taken),基本上是“零开销”的 —— 至少在这款 CPU 上是这样。
到目前为止,我们已经确定了总是执行的分支会占用 BTB,而从未执行的分支则不会。那么其他控制流指令呢,比如call?
我没能在文献中找到这一点,但似乎 call/ret 也需要 BTB 条目来获得最佳性能。我能够在我们的 AMD EPYC 上说明这一点。让我们看一下这个测试。
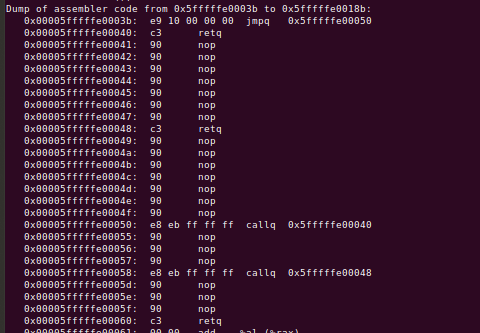
这次我们将发出一些callq指令,然后是ret - 这两个指令都应该被完全预测到。这个实验是精心设计的,所以每个 callq 调用一个独特的函数,用于让 retq 预测 - 每一个都正好返回给一个调用者。
这个图表证实了理论:无论代码密度如何,除了 64 字节的块大小明显较慢外,已经预测的 call/ret 的成本在 2048 个标志之后开始恶化。此时,BTB 已经被 call 和 ret 的预测所填满,不能再处理任何数据。这让我们得出了一个重要的结论。
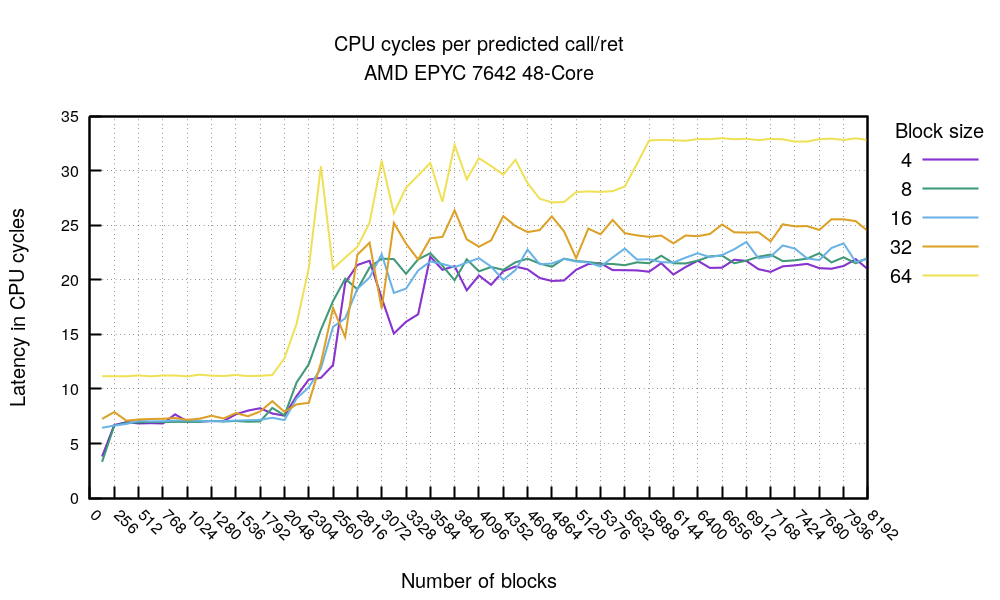
提示 3:在热点代码中,函数调用次数最好少于 2000 次 —— 至少在这款 CPU 上是这样。
在我们的测试 CPU 中,一连串完全预测的 call/ret 需要大约 7 个周期,这与两个无条件预测的jmp操作码差不多。这与我们上面的结果一致。
到目前为止,我们已经对 AMD EPYC 7642 做了全面测试。之所以从这款 CPU 开始,是因为它的 分支预测器相对简单,生成的图表也更容易解读。事实证明,在 较新的 CPU 上,情况就没那么直观了。
AMD EPYC 7713
较新的 AMD 比前几代更加复杂。让我们来运行两个最重要的实验。首先是 jmp 的那个。
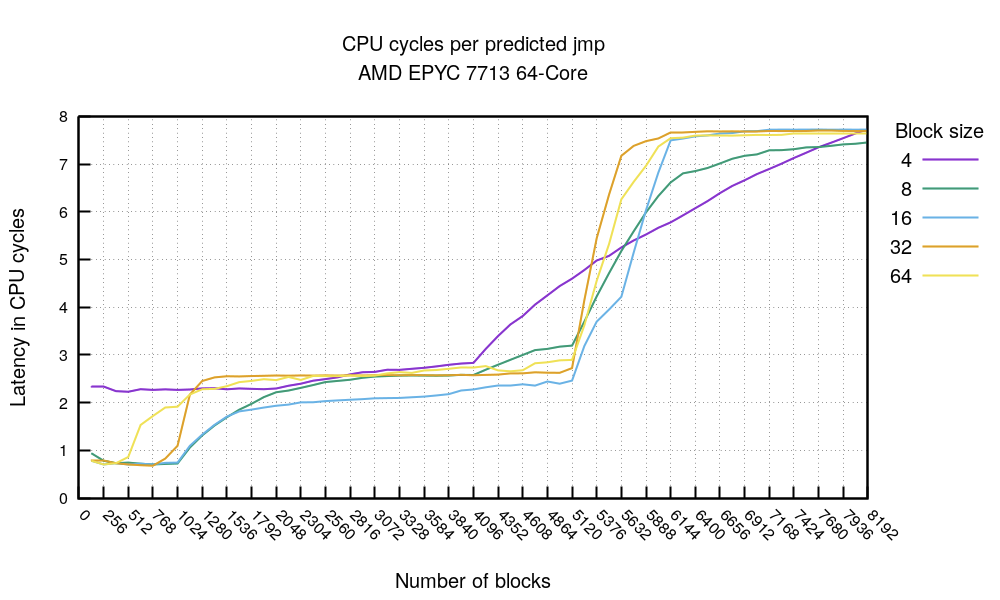
对于总是执行分支的情况,我们可以看到性能非常好:当分支数量不超过 1024 且代码不算太密集时,耗时甚至低于 1 个时钟周期。
提示 4:在这颗 CPU 上,如果热点循环能够小于 32KiB ,那么每个被预测的 jmp 指令的开销可以低于 1 个时钟周期。
接着,在 4096 次跳转(jmps) 之后开始出现一些噪声。随后,在大约 6000 个分支时,性能出现了完全的下降。这与理论相符——即 BTB(分支目标缓冲,Branch Target Buffer) 的容量为 4096 项。我们可以推测,在超过这个点后,某种其他的预测机制成功介入,从而将性能维持到了大约 6000 的水平。
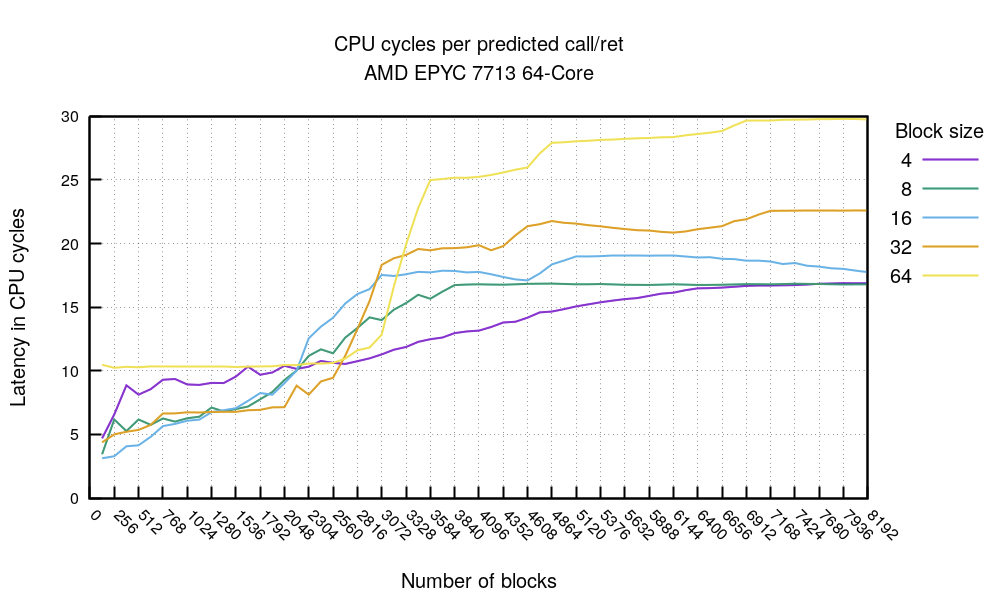
call/ret 图表 展示了类似的情况:在 2048 之后,执行时间开始出现异常;而在大约 3000 之后,则完全无法被正确预测。
Xeon Gold 6262
Intel Xeon 看起来与 AMD 不同。
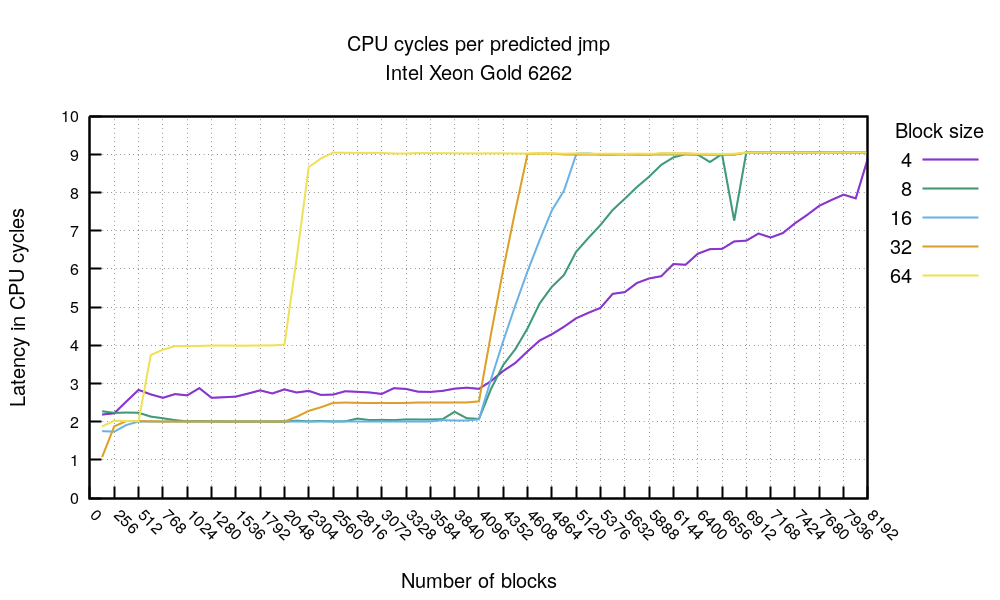
我们的测试表明,被预测为跳转的分支花费 2 个时钟周期。Intel 的文档中提到过,对于分支非常密集的代码会有额外的时钟惩罚 — 这就解释了 4 字节块大小 的曲线为什么稳定在大约 3 个时钟周期。在 4096 次跳转(jmp) 时,分支开销出现突变,这印证了 Intel BTB(Branch Target Buffer,分支目标缓冲) 容纳 4096 个条目的理论。64 字节块大小的图表看上去有些让人困惑,但实际上很好理解:在跳转数达到 512 之前,分支开销始终稳定在 2 个时钟周期,之后才开始上升。这是因为 BTB 的内部结构是 8 路组相联(8-way associative)。看起来,在 64 字节块大小 的情况下,我们最多只能利用 4096 个 BTB 槽位中的一半。
提示 5:在 Intel 处理器上,应避免将 jmp/call/ret 指令放置在固定的 64 字节间隔位置。
然后是 call/ret 图:
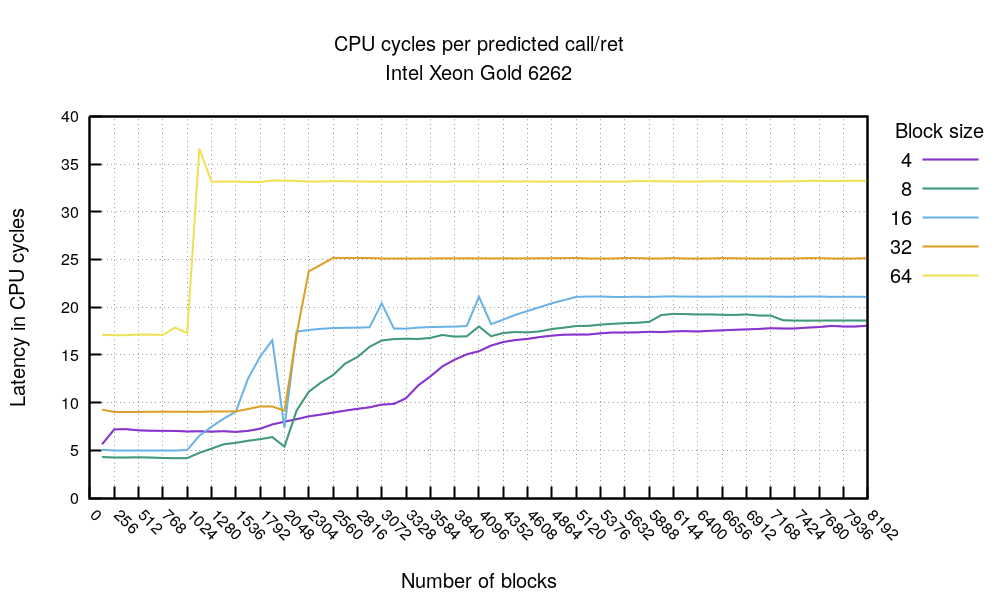
同样地,我们可以看到在 2048 次跳转(jmp) 之后,分支预测开始失效 - 在这个实验中,一个代码块使用了两条控制流指令:call 和 ret。这再次印证了 BTB 的容量为 4K 条目。64 字节块大小 的情况通常更慢,这是由于 nop 填充带来的开销,同时也因为指令对齐问题,而更早失效。需要注意的是,我们在 AMD 处理器上并没有观察到这种现象。
Apple Silicon M1
到目前为止,我们已经看过 AMD 和 Intel 服务器级 CPU 的示例。那么 Apple Silicon M1 在这个对比中表现如何呢?
我们预计它将非常不同 - 因为它是为移动设备设计的,并且使用 ARM64 架构。让我们看看我们的两个实验。
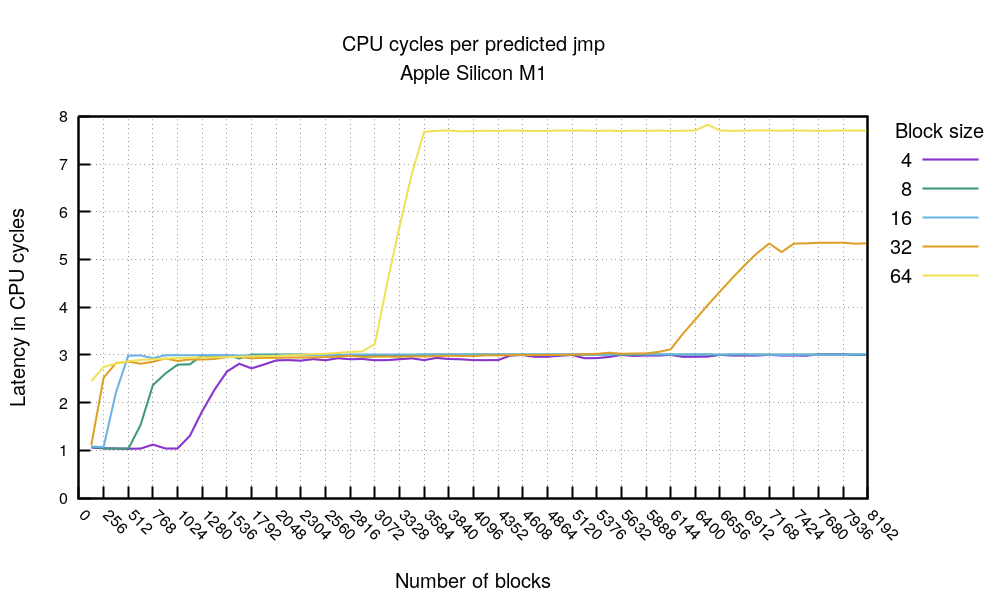
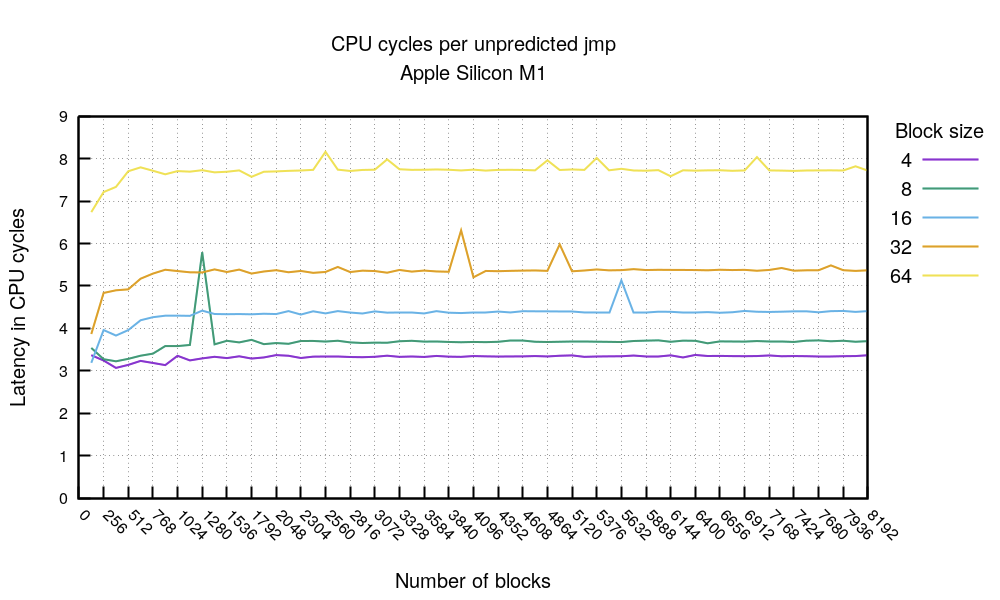
预测的jmp测试显示了一个有趣的故事。首先,当代码适合4096字节(10244或5128,等等)时,你可以期望预测的jmp花费1个时钟周期。这是一个很好的成绩。
被预测的 jmp 测试展示了一个有趣的情况。首先,当代码大小能容纳 4096 字节(如 1024×4 或 512×8 等)时,被预测的 jmp 指令的开销可以达到 1 个时钟周期。这是一个非常优秀的表现。
除此之外,一般来说,你可以期望每个预测的jmp花费3个时钟周期。这也是非常好的。当工作代码增长到200KB以上时,情况就开始恶化了。这一点在块大小为64的3072标记处可以看到,307264=196K,而块大小为32的6144处可以看到:614432=196K。在这一点上,预测似乎停止了工作。文件显示,M1 CPU有192 KB L1的指令缓存–我们的实验与此相符。
超过这个范围后,一般来说,每个被预测的 jmp 指令的开销约为 3 个时钟周期。这依然是非常不错的表现。当工作代码量超过约 200KiB 时,性能开始下降。具体表现为:64 字节块 在 3072 个跳转时出现失效(3072×64 = 196KiB),32 字节块 在 6144 个跳转时出现失效(6144×32 = 196KiB)。此时,预测似乎停止了工作。文档显示,M1 CPU 的 L1 指令缓存大小为 192 KiB — 我们的实验结果与此相符。
让我们把 “被预测的 jmp” 与 “未预测的 jmp” 图表进行比较。不过看这个图表时需要 谨慎对待,因为清空分支预测器一直是非常困难的操作。
然而,即使我们不完全信任 清空 BPU 代码(改编自 Matt Godbolt),这个图表仍然揭示了两点。首先,”未预测”分支的开销似乎与分支距离有关:分支越长,开销越大。这种行为在 x86 CPU 上并未观察到。
然后是成本本身。我们看到一个预测的分支序列的成本,以及一个所谓的未预测的jmp成本。在第一个图表中,我们看到超过192KiB的工作代码,分支预测器似乎变得无效了。所谓的刷新的BPU似乎也显示了同样的成本。例如,一个小工作集大小的64字节块大小的jmp的成本是3个周期。失败则是8个周期。对于一个大的工作集大小,两个时间都是8个周期。看来,BTB与L1缓存的状态有关。Paul A. Clayton早在2016年就提出了这种设计的可能性。
接下来是开销本身。我们已经看过被预测的分支序列开销,以及所谓未预测的 jmp 开销。在第一个图表中,我们看到当工作代码量超过约 192KiB 时,分支预测器似乎失效。所谓被刷新(flushed)的 BPU 也显示出类似的开销。例如,对于 64 字节块大小的 jmp,在工作集较小的情况下开销为 3 个时钟周期;而一次未命中(miss)的开销约为 8 个时钟周期。当工作集较大时,两者的开销都约为 8 个时钟周期。这表明,BTB 可能与 L1 指令缓存的状态相关。Paul A. Clayton 在 2016 年曾提出过这种设计的可能性。
提示 6:在 M1 上,被预测为跳转的分支通常需要 3 个时钟周期,而未预测但实际跳转的分支开销则不固定,取决于跳转距离(jmp length)。BTB 很可能与 L1 指令缓存相关联。
call/ret 的图表很有趣。
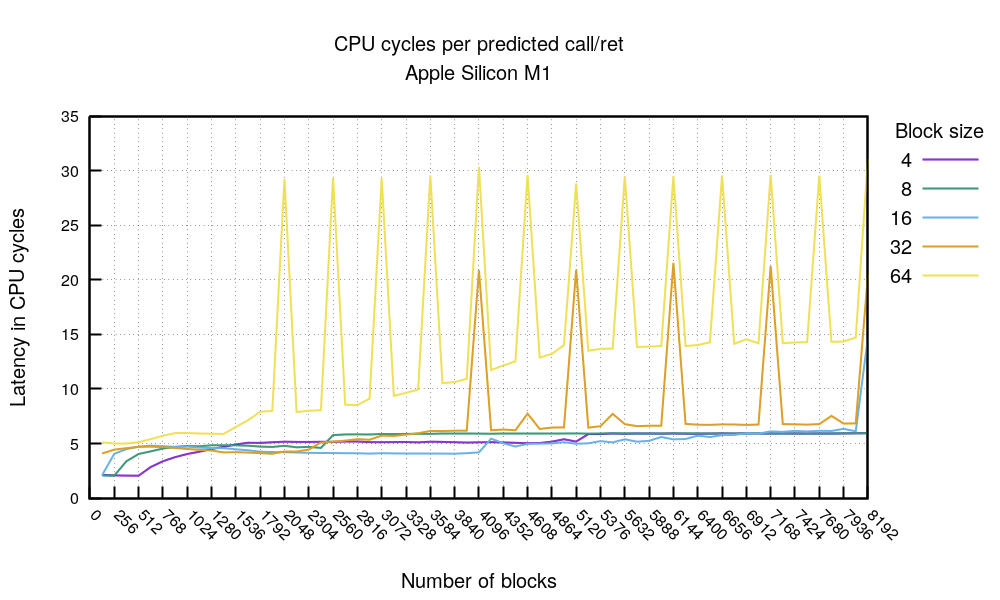
和前面的图表类似,如果热点代码能够在 4096 字节以内(如 512×4 或 256×8),我们可以看到明显的性能优势。否则,每个 call/ret 序列(在 ARM 上称为 bl/ret)的开销大约为 4–6 个时钟周期。图表中显示了一些有趣的对齐(alignment)问题,目前尚不清楚其具体原因。需要注意的是,将这个图表的数据与 x86 对比是不公平的,因为 ARM 的 call 操作与 x86 相差很大。
M1 看起来相当快,被预测的分支通常只需 3 个时钟周期。即使是未预测的分支,在我们的基准测试中开销也从未超过 8 个时钟周期。对于 密集代码的 call+ret 序列,开销应保持在 5 个周期以内。
总结
我们从一段微不足道的代码开始了我们的旅程,并提出了一个基本问题:在代码的热点部分增加一个永远不会执行的 if 分支,代价有多大?
随后,我们很快深入到了 CPU 的底层特性。希望在本文结尾时,有洞察力的读者 能够对 现代分支预测器的工作原理 有更直观的理解。
在 x86 上,热点代码需要在 函数调用 和 被跳转的分支 之间共享 BTB(分支目标缓冲) 的容量。BTB 的总大小仅为 4096 条目。因此,将热点代码控制在 16KiB 以下 可以带来显著的性能优势。
另一方面,在 M1 上,BTB 似乎受 L1 指令缓存 容量限制。如果你在编写超热点代码,理想情况下最好是在 4KiB 内。
最后,你能再加上一个 if 语句 吗?如果它 从未触发,一般没问题。我没有发现任何证据表明这种分支会带来额外开销。但请避免 总是跳转的分支 和 函数调用。
来源
我不是第一个研究 BTB 工作原理的人。我的实验基于以下:
- Vladimir Uzelac 的论文
- Matt Godbolt work. 该系列有5篇文章.
- Real World Tech 网站上的 Travis Downs BTB questions
- 各种 stackoverflow 讨论. 尤其是 这篇 和 这篇
- Agner Fog 微架构指南有一个写的很棒的关于分支预测的章节.
附录
哦,等等,这还不是全部!类似的研究正是 Spectre v2 攻击的基础。该攻击利用了一个鲜为人知的事实:BPU(分支预测单元)的状态在上下文切换时并不会被清除。通过正确的技术,可以对 BPU 进行”训练” — 在 Spectre 的案例中,是 iBTB — 从而迫使特权代码被推测性执行。结合 缓存侧信(side-channel) 数据泄漏,这使得攻击者能够从特权内核中窃取机密信息。这真是非常强大的技术。
一种提出的解决方案是,避免使用共享 BTB。这可以通过两种方式实现:
- 让间接跳转(indirect jumps)总是无法预测;
- 对 CPU 进行修正,避免在隔离域之间共享 BTB 状态。
这是一个很长的话题,也许留到下次再讲……
[^1]: 针对这个特定的 “if debug” 问题,历史上有一种解决方案称为 “运行时 nop 替换(runtime nop’ing)”。其思路是在运行时修改代码,将 从未跳转的分支指令 替换为 nop。例如,可参考 Mozilla Bugzilla 上的 “ISENABLED” 讨论
[^2]: 趣闻:现代编译器非常智能。新的 gcc(>=11)和旧的 clang(>=3.7)实际上可以对这种情况做大量优化。自己试试看就知道了。但别被这个分心了——本文讨论的是 底层机器码的分支指令!
[^3]: 这是一个简化的分类。当然,控制流指令还有更多类型,例如 软件中断(software interrupts)、系统调用(syscalls)、VMENTER/VMEXIT 等。
[^4]: 好吧,我对图表有些过度解读。也许 4096 跳转标记 是由 4096 uop 缓存 或某些指令解码器特性引起的?为了证明这个尖峰确实与 BTB 相关,我查看了 Intel 的 BPUCLEARS.EARLY 和 BACLEAR.CLEAR 性能计数器。结果显示,当块数量低于 4096 时,该值很小,而块数量超过 5378 时,该值很大。这强烈表明性能下降确实由 BPU 引起,并且很可能与 BTB 相关。