
Cloudflare 在 2019年7月2日全球宕机的详细细节,文章揭露了宕机的原因、处理的过程、及后续改进措施,宕机的原因是因为工程师更新了一条WAF的正则表达式,这个表达式造成失控的回溯,使CPU资源耗尽,从而导致服务中断。
Cloudflare Blog 官方中文版:https://blog.cloudflare.com/details-of-the-cloudflare-outage-on-july-2-2019-zh/
原文地址:https://blog.cloudflare.com/details-of-the-cloudflare-outage-on-july-2-2019/
原文标题:Details of the Cloudflare outage on July 2, 2019
原文作者:John Graham-Cumming
原文写于:12 Jul 2019
译者:驱蚊器喵#ΦωΦ
翻译水平有限,有不通顺的语句,请见谅。
大约九年前,Cloudflare 还是一家小公司的时候,我只是客户而不是一名员工。Cloudflare 已经在一个月前发布了产品,有一天警报告诉我,我的小网站 jgc.org 的 DNS 似乎不起作用了。Cloudflare 推翻了对 Protocol Buffers 的使用,这个改变破坏了 DNS。
我直接给 Matthew Prince 写了一封电子邮件,标题名为 “我的 dns 去哪儿了?”,他回复了一封长长的、详细的、技术性的回复(你可以在这里阅读完整的电子邮件交流),对此我回复道:
发件人: John Graham-Cumming
时间: Thu, Oct 7, 2010 at 9:14 AM
标题: Re: Where’s my dns?
收件人: Matthew Prince很棒的报告, 谢谢你. 如果有问题的话我会打电话给你。
有时候,当你收集了所有的技术细节后,把这些写为一篇博客文章可能是好的,
因为我认为人们真的很欣赏这些事故的开放和诚实。
尤其是,如果你把文章与图表结合起来发布,访问流量将会迅猛的增加。我对我的网站有非常强大的监控,所以当网站一切都挂掉后,我会收到告警的短信。
监控显示,我的网站在 13:03:07 到 14:04:12 停止运行。
测试是每五分钟进行一次。这是一个小波动,我相信你会度过这个事件的。但你确定你在欧洲不需要有人帮忙吗?:-)
From: John Graham-Cumming
Date: Thu, Oct 7, 2010 at 9:14 AM
Subject: Re: Where’s my dns?
To: Matthew PrinceAwesome report, thanks. I’ll make sure to call you if there’s a
problem. At some point it would probably be good to write this up as
a blog post when you have all the technical details because I think
people really appreciate openness and honesty about these things.
Especially if you couple it with charts showing your post launch
traffic increase.I have pretty robust monitoring of my sites so I get an SMS when
anything fails. Monitoring shows I was down from 13:03:07 to
14:04:12. Tests are made every five minutes.It was a blip that I’m sure you’ll get past. But are you sure you
don’t need someone in Europe? :-)
对此,他的回复:
发件人: Matthew Prince
时间: Thu, Oct 7, 2010 at 9:57 AM
标题: Re: Where’s my dns?
收件人: John Graham-Cumming谢谢。 我们已经给每个写邮件的人发送了回复。我现在要前往
办公室,并且我们会在博客上写一点东西,或者是在我们的公告板系统置顶一个官方通告
我同意 100% 的公开透明是最好的做法。
From: Matthew Prince
Date: Thu, Oct 7, 2010 at 9:57 AM
Subject: Re: Where’s my dns?
To: John Graham-CummingThanks. We’ve written back to everyone who wrote in. I’m headed in to
the office now and we’ll put something on the blog or pin an official
post to the top of our bulletin board system. I agree 100%
transparency is best.
所以,今天,作为一个更庞大的 Cloudflare 公司的员工,我会成为那个写下事故报告的人,透明地讲述我们犯下的错误,错误带来的影响,以及我们正在做的事情。
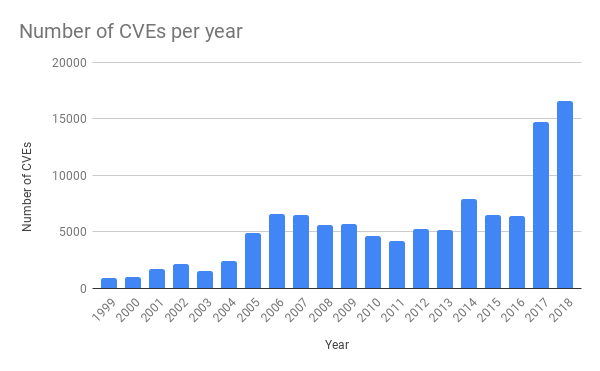
7月2日的事故
在7月2日,我们在 WAF 管理规则中部署了一条新规则,导致在每个处理 Cloudflare 全球网络上 HTTP/HTTPS 流量的 CPU 核心上的 CPU 耗尽了资源。我们不断改进 WAF 管理规则以应对新的漏洞和威胁。例如,在5月份,我们利用 WAF 快速更新的优势,来让我们能够发布规则,用于防范严重的 SharePoint 漏洞。能够迅速的全局部署规则是我们 WAF 的一个重要特性。
不幸的是,上周二的更新包含的一个正则表达式,该表达式极大地回溯并耗尽了用于 HTTP/HTTPS 服务的 CPU 资源。这使得 Cloudflare 的核心代理,CDN 和 WAF 功能 宕机。下图显示了专用于提供 HTTP/HTTPS 流量的 CPU,这些 CPU 在我们网络中的服务器上使用率接近 100%。
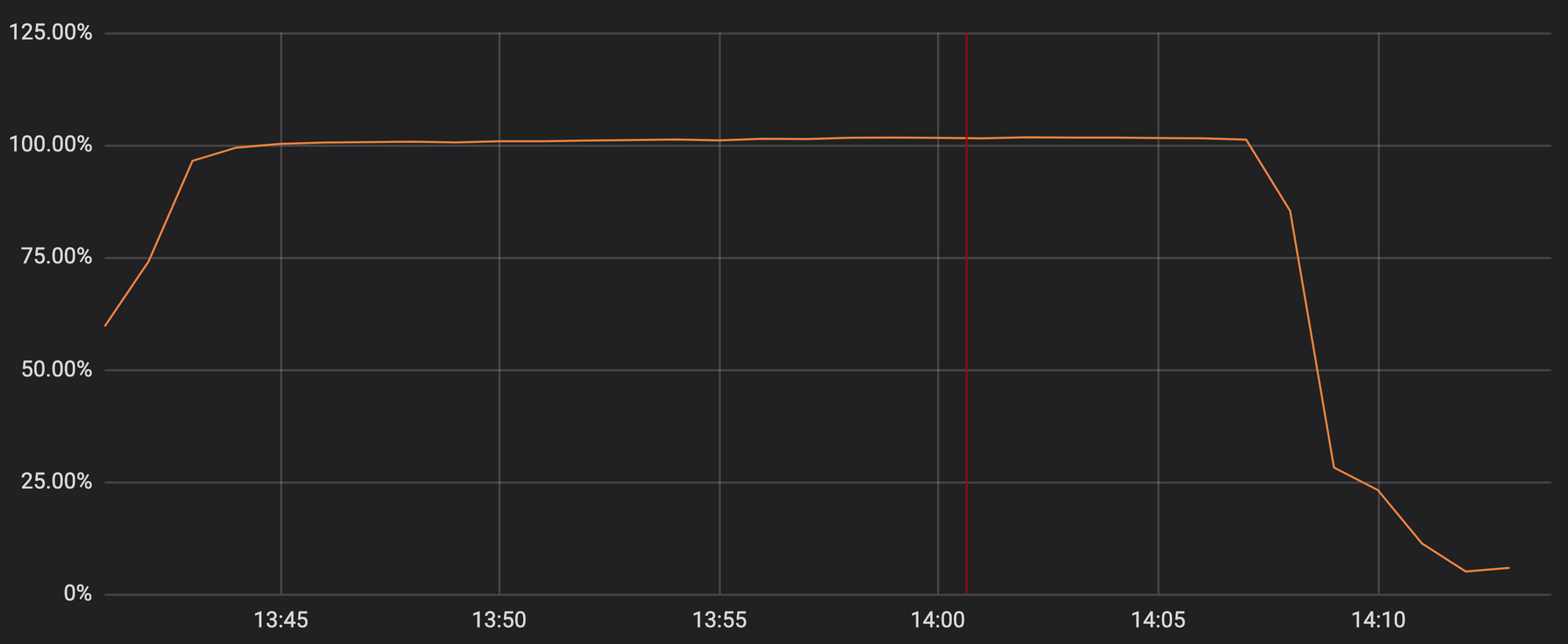
这导致我们的客户(以及他们的客户)在访问任何 Cloudflare 域时看到 502 错误页面。502 错误是由前线 Cloudflare Web 服务器生成的,这些服务器仍然具有可用的CPU 核心,但无法访问提供 HTTP/HTTPS 流量的进程。
我们知道这对我们的客户造成了多大的伤害。对此我们感到羞愧。在我们处理这一事件时,它也对我们自己的运营产生了负面影响。
如果您是我们的客户之一,那你一定是承受了令人难以置信的压力,沮丧和害怕。更令人沮丧的是,因为我们已经六年没有发生过全球宕机的事故。
CPU 耗尽是由一个 WAF 规则引起的,该规则包含了一个写得糟糕的正则表达式,最终导致过多的回溯。造成了宕机的核心正则表达式是这样:
1 | (?:(?:\"|'|\]|\}|\\|\d|(?:nan|infinity|true|false|null|undefined|symbol|math)|\`|\-|\+)+[)]*;?((?:\s|-|~|!|{}|\|\||\+)*.*(?:.*=.*))) |
虽然很多人对正则表达式本身很感兴趣(下面将对此进行详细讨论),但 Cloudflare 服务停止了27分钟的真实故事要比”不完善的正则表达式”复杂得多。我们花时间写出导致服务中断的一系列事件,这些事件阻止我们快速响应。而且,如果您想了解有关正则表达式回溯的更多信息,以及如何处理它,那么您可以在本文末尾的附录中找到它。
发生了什么
让我们从事件的顺序开始。本博客中的所有时间时区都是 UTC。
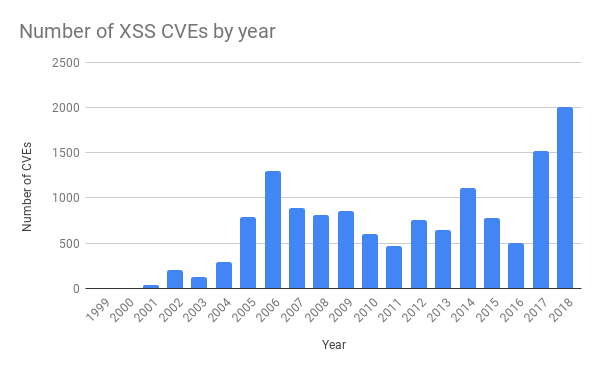
在 13:42,一名在防火墙团队工作的工程师,通过自动处理过程对 XSS 检测规则进行了一些微小的改动。这生成了变更请求(Change Request)的工单。我们使用 Jira 来管理这些工单,下面是截图。
三分钟后,第一个 PagerDuty 页面出现,表明 WAF 有问题。这是一个综合测试,它检查来自 Cloudflare 外部的 WAF(我们有数百个这样的测试)的功能,以确保它正常工作。紧随其后的是页面,其中显示了许多 Cloudflare 服务的其他端到端测试失败,一个全球流量丢弃警报,普遍的502 错误,以及来自全球城市中我们的入网点(points-of-presenc,PoP)的许多报告,表明存在 CPU 资源耗尽。


其中一些警报出现在我的手表上,我从我所在的会议离开,并回到了我的办公桌,解决方案工程部门的一位负责人告诉我,我们已经丢失了 80% 的流量。我跑到 SRE 那边,团队正在调试情况。在宕机(outage)的最初时刻,有人猜测这是我们以前从未见过的某种类型的攻击。

Cloudflare 的 SRE 团队遍布全球,并且持续24小时覆盖。这些警报,其中绝大多数都注重为局部区域范围有限的非常具体的问题,我们在内部仪表板中进行监控,并且每天都要进行多次处理。然而,这种页面和警报模式表明发生了严重的问题,SRE 立即宣布了 P0 事件,并升级为工程领导和系统工程。
当时伦敦工程团队正在我们的主要活动场所听取内部技术讲座。谈话被打断了,每个人都聚集在一个大型会议室,其他人拨打了电话。这不是 SRE 单独处理的正常问题,它需要每个相关团队立即联机。
在 14:00 时,确定是导致问题的组件是 WAF,并且排除了被攻击的可能。性能团队从一台清楚显示 WAF 负责的机器中提取了实时 CPU 数据。另一名团队成员使用 strace 确认。另一个团队看到了错误日志,表明 WAF 遇到了麻烦。在 14:02 时,当提议我们使用“全局终止(global kill)”时,整个团队都在看着我,这是一种内置于 Cloudflare 中的机制,用于禁用全球范围内的单独组件。
但是,使用全局终止 WAF 是另一回事。麻烦阻挡我们。我们通过我们的 Access 服务使用自己的产品,现在服务停止,我们无法对我们的内部控制面板进行身份验证(一旦我们重新得到访问权限,我们发现团队中的某些成员失去了访问权限,因为他们不经常使用内部控制面板,所以安全功能禁用了他们的凭据)。
而且我们无法访问其他内部服务,如 Jira 或构建系统。为了访问它们,我们不得不使用一种不经常使用的旁路机制(在事件发生后还需继续钻研)。最终,一名团队成员在 14:07 执行了 WAF 的全局终止,并且在14:09 ,全球范围内的流量等级和 CPU 回到了的预期水平。Cloudflare 的其余保护机制继续运作。
然后我们回到恢复 WAF 功能的这件事上。由于这种情况的敏感性,我们在一个单独的城市中,移除了我们的付费客户的流量,使用了一小部分的流量进行了消极测试(negative tests)(拷问我们自己“是否真的是此项特定更改造成了问题?”)以及积极测试(positive tests)(验证回滚是否有效)。
在 14:52,我们了解原因并进行了修复,我们 100% 确认后,在全球范围内重新启用了 WAF。
Cloudflare 如何运作
Cloudflare 拥有一支工程师团队,负责我们的 WAF 管理规则产品; 他们不断得致力于提高检测率,降低误报,并在新威胁出现时迅速做出反应。在过去的 60 天里,已经为 WAF 管理规则处理了 476 个变更请求(平均每3个小时一个)。
此项特定更改将以“模拟”模式来部署,其中真实客户流量通过规则,但不会有任何阻止。我们使用该模式来测试规则的有效性,并测量其误报(false positive)和漏报(false negative)的概率。但是,即使在模拟模式下,规则实际上也需要执行,在这样的情况下,那项规则即是包含一个消耗过多 CPU 的正则表达式。
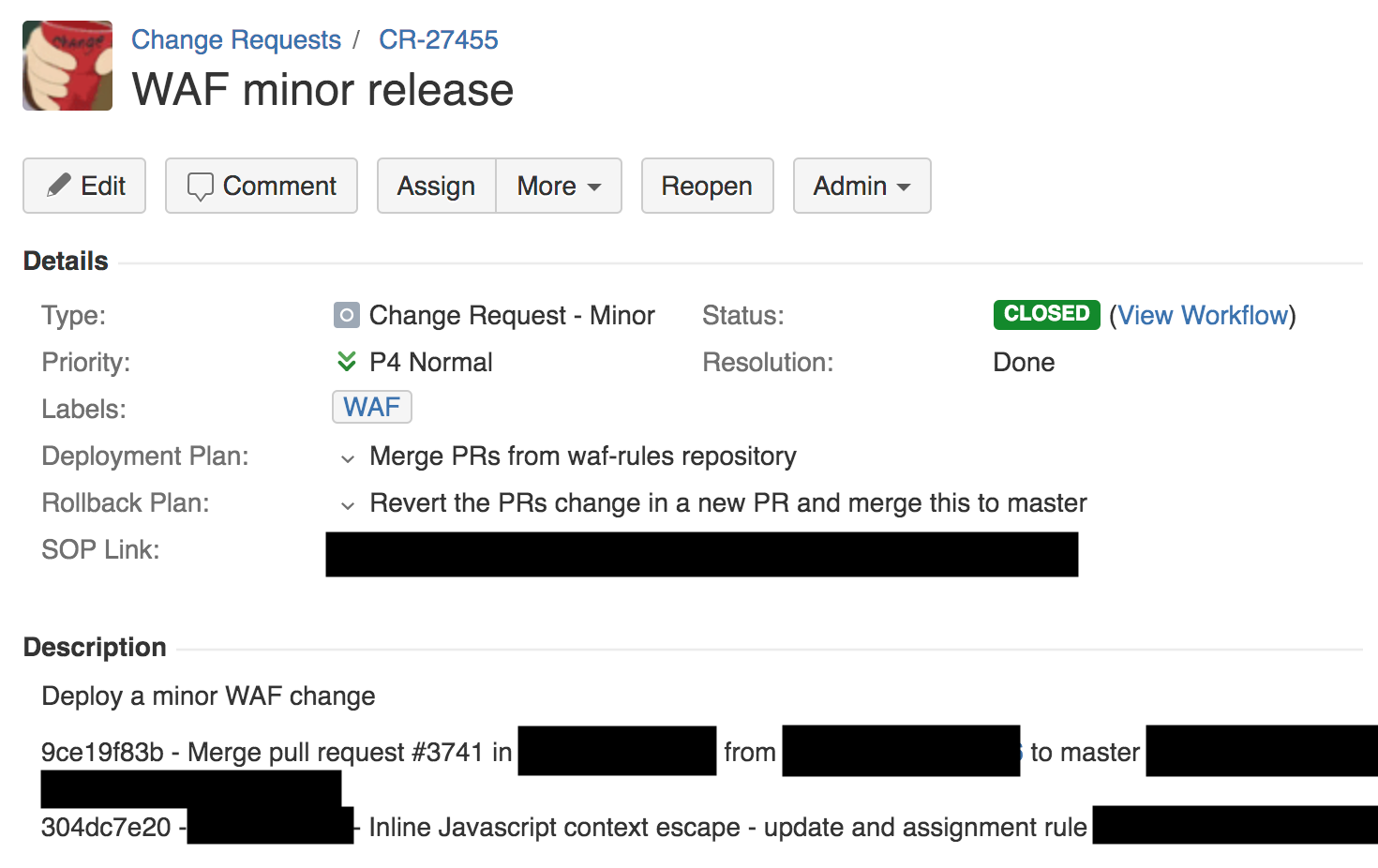
从上面的变更请求(Change Request)可以看出,上面有一个部署计划,一个回滚计划,和一个指向此类部署的内部标准操作过程(Standard Operating Procedure,SOP)的链接。更改规则的 SOP 特别地允许了可以全局推送。这与我们在 Cloudflare 发布的所有软件非常地不同,SOP 首先将软件推送到内部 dogfooding 网络存在点(point of presence,PoP)(我们的员工通过这里),然后是隔离位置的少数客户,其次通过推动大量客户,最终推送到全世界。
软件版本的过程如下所示:我们在内部通过 BitBucket 使用 git。致力于更改的工程师推送由 TeamCity 构建的代码,当构建通过时,将分配给审计人员。一旦拉取请求(pull request)被批准,代码就会生成,测试套件会(再次)运行。
如果构建和测试通过,则 Jira 生成变更请求(Change Request) ,并且变更必须由相关经理或技术主管批准。一旦被批准,会将部署到我们称之为“动物性 PoP”的地方:DOG,PIG 和 Canaries。
DOG PoP 是 Cloudflare PoP(就像我们在全球任何一个城市一样)但它仅由 Cloudflare 员工使用。这种 dogfooding PoP 使我们能够在任何客户流量触及代码之前及早发现问题。事实也经常如此。
如果 DOG 测试通过成功,代码将转到 PIG(如“豚鼠”)。这是一个Cloudflare PoP,免费客户中的一小部分客户流量在这里穿过新的代码。
如果成功,代码将移至 Canaries。我们在世界各地有三个 Canary PoP,并在新代码上运行付费和免费客户流量作为最终检查错误。
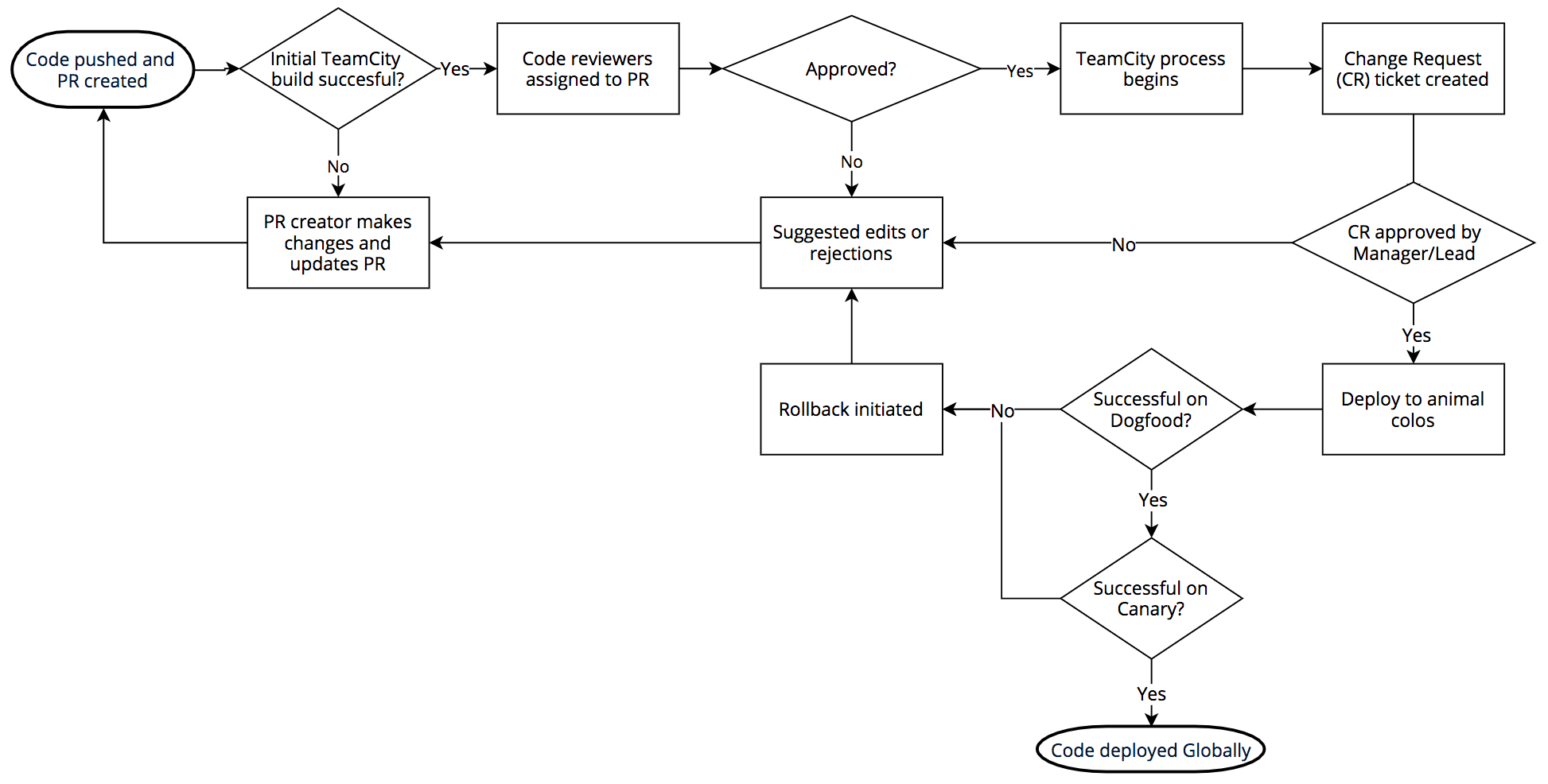
Cloudflare 的软件发布流程
一旦在 Canary 成功,代码就可以上线了。整个 DOG,PIG,Canary,Global 流程可能需要数小时或数天才能完成,具体取决于代码更改的类型。Cloudflare 网络和客户的多样性使我们能够在将版本推送给全球所有客户之前彻底测试代码。但是,根据设计,WAF 不会使用此过程,因为 WAF 需要快速响应威胁。
WAF 威胁
在过去几年中,我们看到常见应用程序中的漏洞急剧增加。这是由于软件测试工具,提高了可用性,如模糊化测试(fuzzing),例如(我们刚刚在博客发布的有关模糊化测试(fuzzing)的文章,你可以在这里查看)。
我们常常看到,概念证明(Proof of Concept,PoC)被创建,并在 Github 上快速发布,以便运行和维护应用程序的团队可以进行测试以确保他们有充分的保护。因此,Cloudflare 必须能够尽快对新的攻击做出反应,以便让我们的客户有机会修补他们的软件。
Cloudflare 主动提供此类保护的一个很好的例子,是在5月份部署我们针对 SharePoint 漏洞的保护措施(文章在这里)。在公布公告的短时间内,我们看到了大量利用我们客户的 Sharepoint 漏洞的尝试行为。我们的团队不断监控新出现威胁,并编写规则以帮助客户缓解这些威胁。
导致上周二服务中断的具体规则是针对跨站点脚本(XSS)攻击。近年来,这些攻击也急剧增加。
WAF 管理规则更改的标准过程表明,持续集成(Continuous Integration,CI)测试必须在全局部署之前通过。这发生在上周二,并且规则已经部署。在13:31,团队中的工程师在批准后合并了包含更改的 Pull Request。
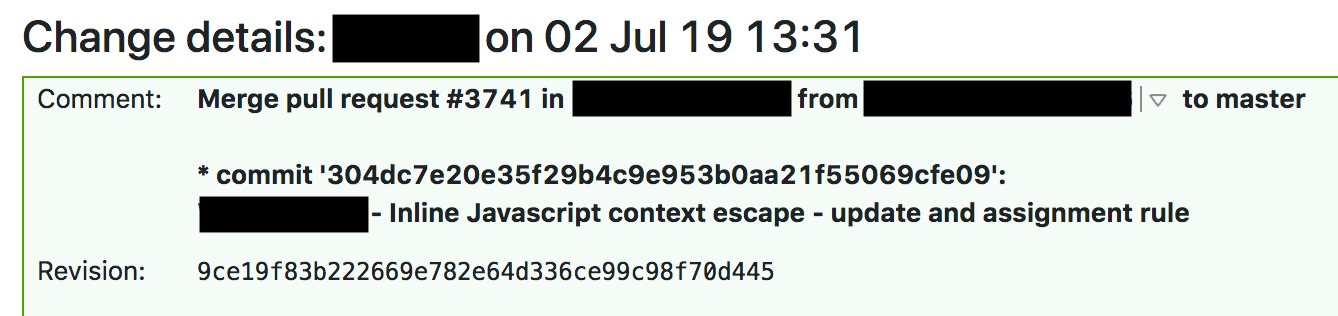
在 13:37,TeamCity 构建了规则并运行测试,然后测试结果为绿灯。WAF 测试套件测试了 WAF 的核心功能,并进行了包含大量单独匹配功能的单元测试。在单元测试运行之后,通过对 WAF 执行大量 HTTP 请求来测试各个 WAF 规则。这些HTTP 请求被用于测试应该被 WAF 阻止的请求(以确保它能够捕获攻击)以及应该通过的请求(以确保它不会过度阻塞并产生误报)。它没有做的是,测试 WAF 失控的 CPU 利用率,并且检查以前的 WAF 版本中的日志文件,确保测试套件运行时间没有增加,防止导致 CPU 耗尽的规则。
测试通过后,TeamCity 在 13:42 开始自动部署更改。
Quicksilver
由于 WAF 规则需要用于解决紧急的威胁,因此使用我们的 Quicksilver 分布式键值(key-value,KV)存储来部署它们,这些存储可以在几秒钟内全局推送更改。在我们的仪表板中,或通过 API 进行配置更改时,我们的所有客户都使用此技术,这是我们服务能够非常快速地响应变更的支撑。
我们还没有真正谈论过 Quicksilver。我们以前使用 Kyoto Tycoon 作为全球分布式的键值存储,但我们运行时遇到了问题,所以编写了我们自己的 KV 存储,这些存储的副本存放在 180 多个城市中。我们如何推送客户配置更改,更新 WAF 规则,以及使用 Cloudflare Workers 分发客户编写的 JavaScript 代码,Quicksilver 是其中的关键。
通过单击仪表板中的按钮,或进行 API 调用,来将配置更改,到该更改全局生效只需要几秒钟。客户已经开始喜欢这种快速性的配置功能。而对于 Workers,他们期望近乎即时的全球软件部署。平均而言,Quicksilver 每秒分发约 350 次更改。
而且 Quicksilver 非常快。平均而言,我们达到了 2.29 秒的 p99,以便将更改分发给全球的每台机器。通常,这种速度是一件好事。这意味着当您启用某项功能,或清除缓存时,您知道它几乎可以立即在全球范围内生效。当您使用 Cloudflare Workers 推送代码时,它会以相同的速度推送出去。这是 Cloudflare 在您需要时快速更新承诺的一部分。
但是,在这种情况下,这种速度意味着规则的变化在几秒钟内就会变得全球化。您可能会注意到 WAF 的代码使用的是 Lua。Cloudflare 在生产中广泛使用 Lua,之前已经讨论过 WAF 中 Lua 的细节。Lua WAF 在内部使用 PCRE,它使用回溯(backtracking)进行匹配,没有机制来防止失控的表达式。在下面会讲述关于这一点以及我们做了些什么更多信息。

在部署规则之前发生的所有事情都是“正确”完成的:提出拉取请求,批准,CI/CD 构建代码并对其进行测试,提交了一个带有 SOP 详细说明部署和回滚的变更请求,并且执行了部署。
什么地方出了错
如上所述,我们每周都会向 WAF 部署数十条新规则,并且我们有许多系统可以防止该部署产生任何负面影响。因此,当事情出错时,通常不会出现多种原因。在满足的同时找到一个根本原因可能会掩盖现实。以下是组合在一起的多个缺陷,使得 Cloudflare 的 HTTP/HTTPS 服务离线。
- 一位工程师写了一个很容易回溯的正则表达式.
- 在 WAF 活动周重构之前,错误地删除了一个有助于防止正则表达式过度使用 CPU的保护 - 重构是使 WAF 使用更少 CPU 计划的一部分。
- 正在使用的正则表达式引擎没有复杂性保证。
- 测试套件没有办法识别 CPU 的过多消耗。
- SOP 允许非紧急规则变更在全球投入生产,而无需分阶段推出。
- 回滚计划需要花费太长时间,因为需要运行两次完整的 WAF 构建
- 全球流量丢弃的第一个警报耗时太长(too long to fire)。
- 我们没有足够及时地更新我们的状态页面。
- 由于宕机和旁路程序没有经过良好的训练,我们很难访问我们自己的系统。
- SRE 们失去了对某些系统的访问权限,因为出于安全考虑,他们的凭据已超时。
- 我们的客户无法访问 Cloudflare Dashboard 或 API,因为他们需要通过 Cloudflare 边缘服务器。
从上周二起发生了什么
首先,我们完全停止了对 WAF 的所有发布工作,并且正在执行以下操作:
- 重新引入已经移除的 CPU 过多使用保护。(完成)
- 手动检查 WAF 托管规则中的所有 3,868 条规则,以查找并更正可能过度回溯的任何其他实例。(检查完成)
- 为测试套件引入所有规则的性能分析。(预计完成时间:7月19日)
- 切换到 re2 或 Rust 正则表达式引擎,它们都具有运行时保证。(预计完成时间:7月31日)
- 更改 SOP,来按照 Cloudflare 中其他软件使用的相同方式分阶段推出规则,同时保留为主动攻击执行紧急全局部署的能力。
- 实施一项紧急功能,使 Cloudflare Dashboard 和 API 脱离 Cloudflare 的边缘服务器(edge).
- 自动更新 Cloudflare Status 页面。
从长远来看,我们正在远离几年前我写的 Lua WAF。我们正在移植 WAF 到新的防火墙引擎。这将使 WAF 运行得更快,并增加另一层保护。
结论
对我们的客户和团队来说,这次事故是一个令人不安的服务中断。我们迅速做出反应以纠正这种情况,正在纠正导致服务中断发生的流程缺陷,并通过更换所使用的基础技术,来更加深入地防止我们在进一步可使用正则表达式的方式能出现的问题。
我们对宕机感到羞耻,并为我们对客户的影响感到抱歉。我们相信我们所做的改变意味着这类宕机永远不会再发生。
附录: 关于正则表达式的回溯
要全面理解以下正则表达式
1 | (?:(?:\"|'|\]|\}|\\|\d|(?:nan|infinity|true|false|null|undefined|symbol|math)|\`|\-|\+)+[)]*;?((?:\s|-|~|!|{}|\|\||\+)*.*(?:.*=.*))) |
是如何导致 CPU 资源耗尽,您需要了解标准正则表达式引擎的工作原理. 其中的关键部分是 .*(?:.*=.*)。 (?: 和 ) 不是用于捕获的规则组 (即,括号内的表达式被组合在一起作为单个表达式).
为了探讨这种匹配模式导致 CPU 耗尽的原因,我们可以安全地忽略其中的一部分,并将匹配模式(pattern)看作为.*.*=.*。当缩小到这样的范围时,匹配模式显然看起来没有那些不必要的复杂符号; 但重要的部分是那些任何“现实中”的表达式(比如我们的 WAF 规则中的复杂表达),要求正则引擎“匹配任何事物后跟随的任何东西”,都可能导致灾难性的回溯。这就是原因。
在正则表达式中,.表示匹配单个字符,.*表示贪婪地匹配零个或多个字符(即尽可能多匹配),因此.*.*=.*表示匹配零个或多个字符,然后匹配零个或多个字符,接着找到文字=符号,最后匹配零个或多个字符。
我们来假设一个这样的测试字符串,x=x。 这将和表达式.*.*=.*匹配。=之前的.*.*可以匹配第一个x(其中一个.*匹配x,另一个匹配零个字符)。=之后的.*匹配最后的x。
这次匹配需要 23 步才能完成。 .*.*=.*中的第一个.*贪婪地匹配整个x=x字符串。引擎继续考虑下一个.*。 没有剩下的字符可以匹配,所以第二个.*匹配零个字符(这是允许的)。 然后引擎继续前进到=。 由于没有剩下的字符可以匹配(第一个.*消耗了所有的x=x),匹配失败。
此时,正则表达式引擎回溯(backtracks)。它返回到第一个.*并将它与x=(而不是x=x)进行匹配,然后移到第二个.*。 第二个.*匹配到第二个x,现在没有剩下的字符可以匹配了。 所以当引擎试图匹配.*.*=.*中的=时,匹配失败。引擎再次回溯。
这次回溯,第一个.*仍匹配x=但第二个.*不再匹配x; 它匹配零个字符。 然后引擎继续尝试在.*.*=.*的匹配模式中找到=的匹配,但是失败了(因为它已经与第一个.*匹配)。 引擎再次回溯。
这次,第一个.*仅匹配第一个x。但是第二个.*贪婪地匹配了=x。你可以预料到即将发生什么。当它试图匹配=时,它失败了,并再次回溯。
(再次回溯,)第一个.*仍然匹配第一个x。 现在第二个.*只匹配=。但是,你可以猜到,引擎无法匹配=,因为第二个.*已经匹配掉了。所以引擎再次回溯。请记住,这些工作都是为了匹配包含三个字符的字符串。
最后,第一个.*匹配第一个x,第二个.*匹配零个字符,引擎能够匹配表达式中的=和字符串中的=。它继续前进,最后的.*匹配最后的x。
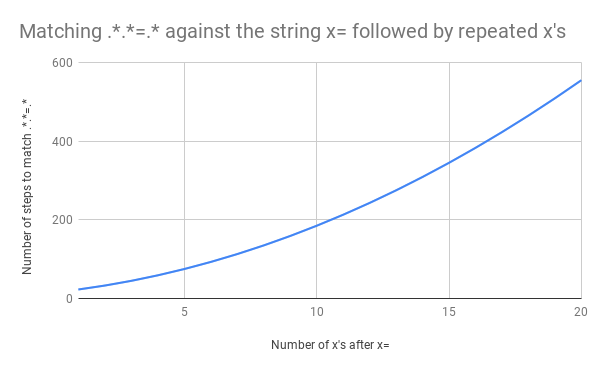
匹配x=x需要 23 步。 以下是使用 Perl Regexp :: Debugger 的简短视频,显示了匹配发生时的步骤和回溯。

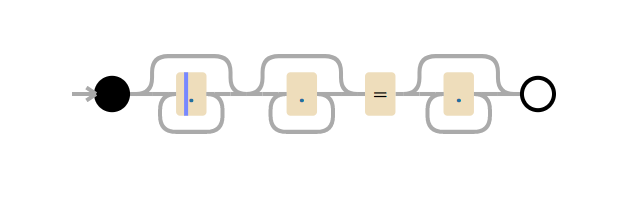
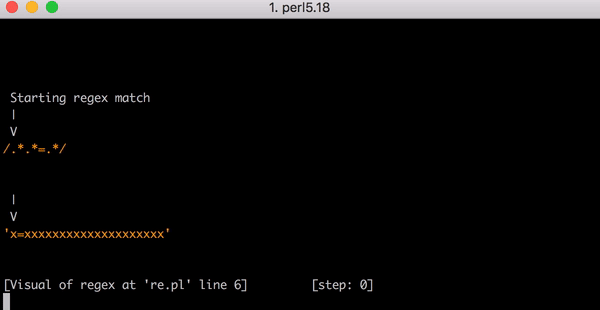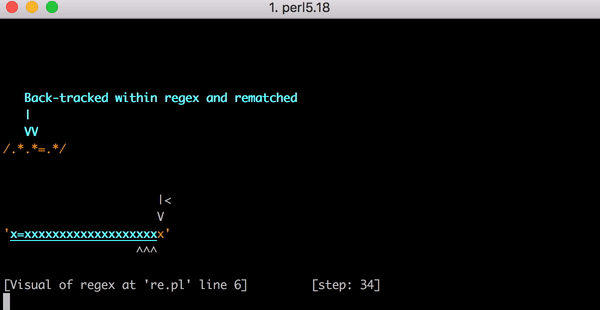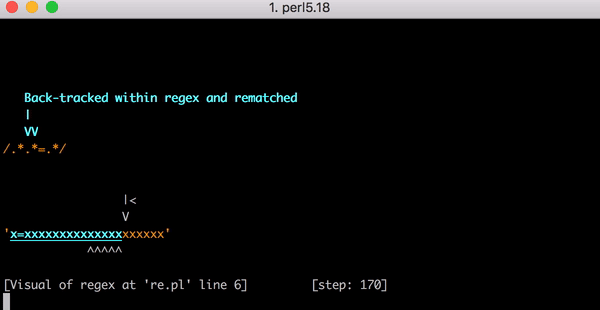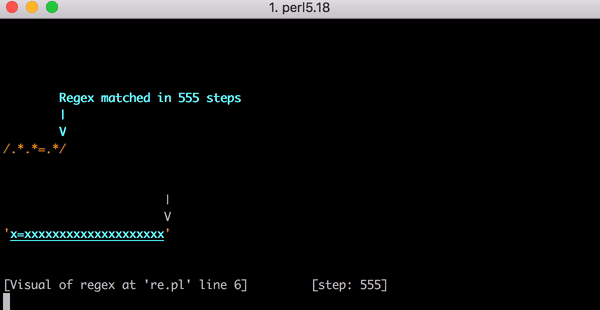
这个工作很多,但如果测试字符串从x=x变为x=xx会发生什么?需要 33 步才能匹配。如果输入内容为x=xxx,则需要45步。这不是线性增长的。以下是一个图表,用于显示从x=x到x=xxxxxxxxxxxxxxxxxxxx(在=之后的20个x)匹配所需的步数。在=之后有 20个x,引擎需要 555 步才能匹配! (更糟糕的是,如果缺少x=,字符串只有20个x,引擎将需要 4,067 步才能得到不匹配的结果)。
此视频显示了匹配x=xxxxxxxxxxxxxxxxxxxxx所需的所有回溯:
这很糟糕,因为随着输入大小的增加,匹配时间将会超线性上升。 但是,事情可能会更糟,因为正则表达式稍有不同。假设正则表达式是.*.*=.*;(也就是,模式末尾有一个分号)。这可能编写用于匹配像foo=bar;这样的表达式。
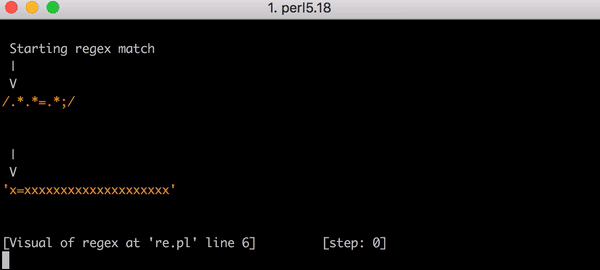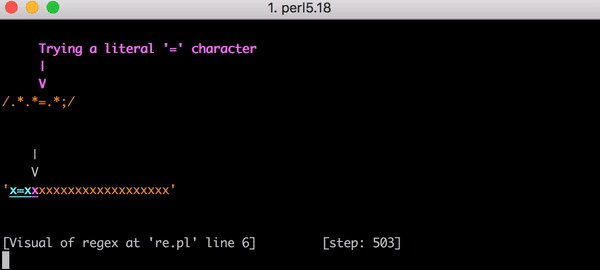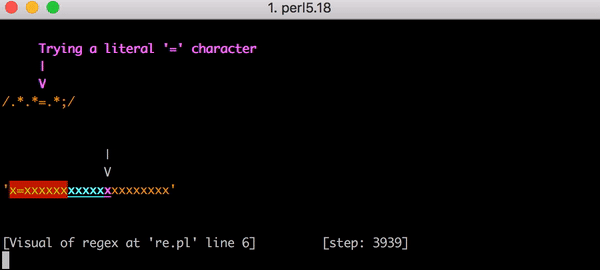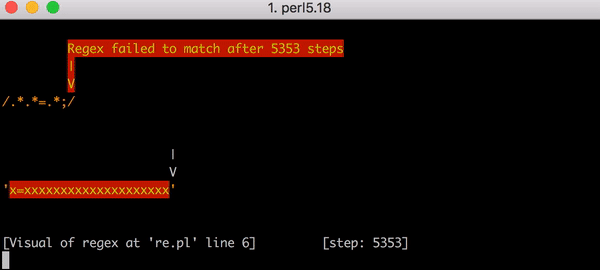
这种情况下,回溯将会是灾难性的。匹配x=x需要 90 步而不是 23 步。步数的个数增长得非常快。匹配x=后跟 20 个x需要 5,353 步。这是对应的图表。仔细查看并比较与前一个图表的 Y 轴值。
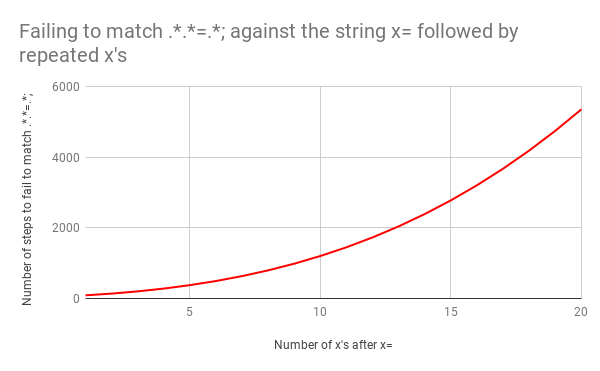
为了完成这里的图表,所有的未能匹配x = xxxxxxxxxxxxxxxxxxxx与.*.*=.*;的 5,353 步如下
使用懒惰(lazy)匹配来代替贪婪匹配,有助于控制在这种情况下发生的回溯次数。如果原始表达式改为.*?.*?=.*?,那么匹配x=x需要 11 步(而不是 23 步),匹配x=xxxxxxxxxxxxxxxxxxxx,回溯次数也是一样。 那是因为.*之后的?,指示引擎在继续之前首先匹配最小数量的字符。
但懒惰匹配并不是这种回溯行为的完全解决方案。将灾难性的例子.*.*=.*;(多了个分号)更改为.*?.*?=.*?;,根本不会改变其运行时间。x=x仍然需要 555 步,x=后跟20个x仍需要 5,353 步。
唯一真正的解决方案是,不再更加具体地完全重写匹配模式,而是摆脱使用这种回溯机制的正则表达式引擎。这是我们在未来几周内要做的事情。
自1968年,Ken Thompson 写了一篇题为“编程技巧:正则表达式搜索算法(Programming Techniques: Regular expression search algorithm)”的论文以来,人们就已经知道了这个问题的解决方案。论文描述了一种机制,用于将正则表达式转换为 非确定性的有限状态机(non-deterministic finite automata,NFA),然后使用一种算法在 NFA 中跟踪状态转换,该算法消耗的时与所匹配的字符串的大小成线性关系。

Thompson 的论文实际上没有讨论 NFA,但是已经清楚地解释了线性时间算法,并且提出了一个为 IBM 7094 生成汇编语言代码的 ALGOL-60 程序。实现过程可能是很难理解的,但它提出的思路却可以很好理解。
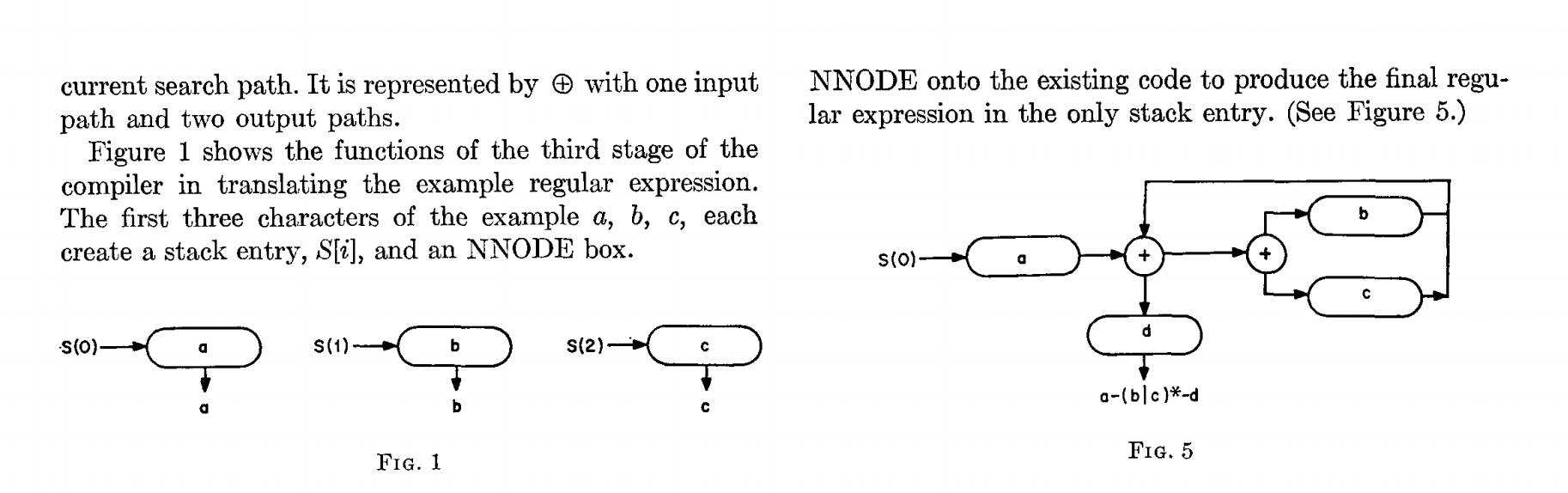
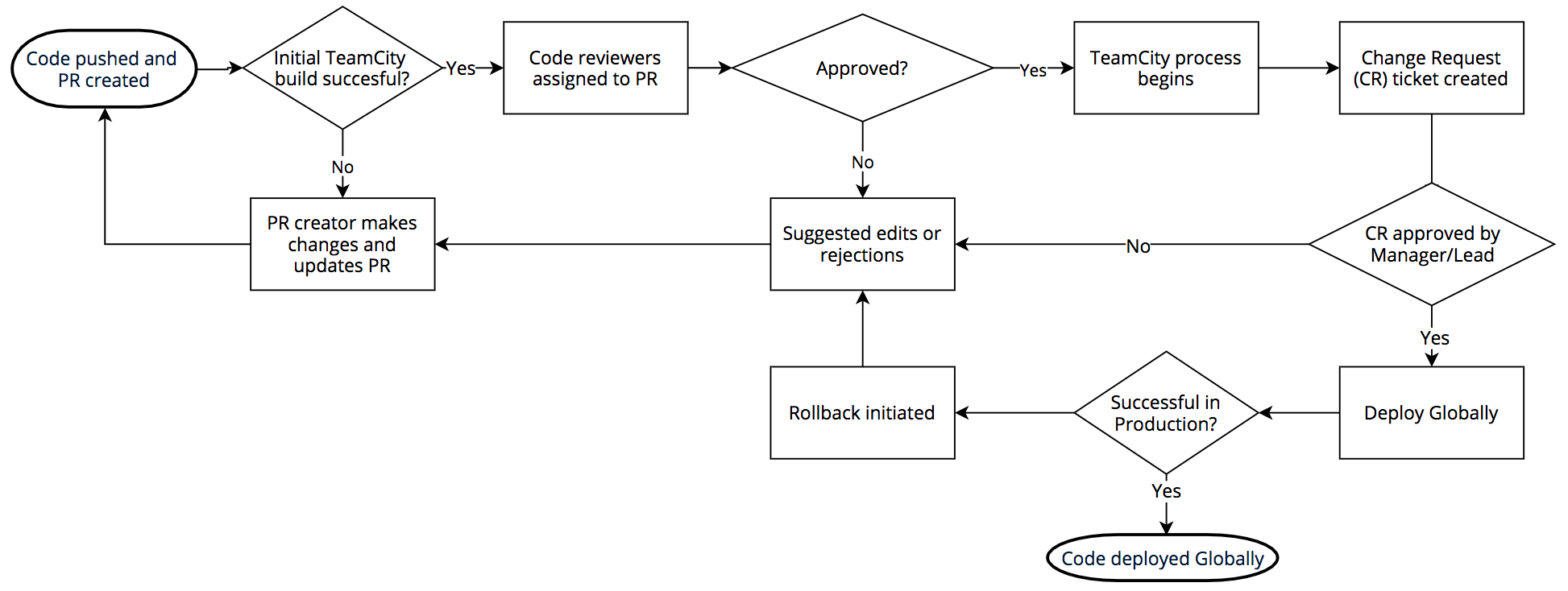
这里的正则表达式.*.*=.*,看起来就像 Thompson 论文中的插图中的那样。
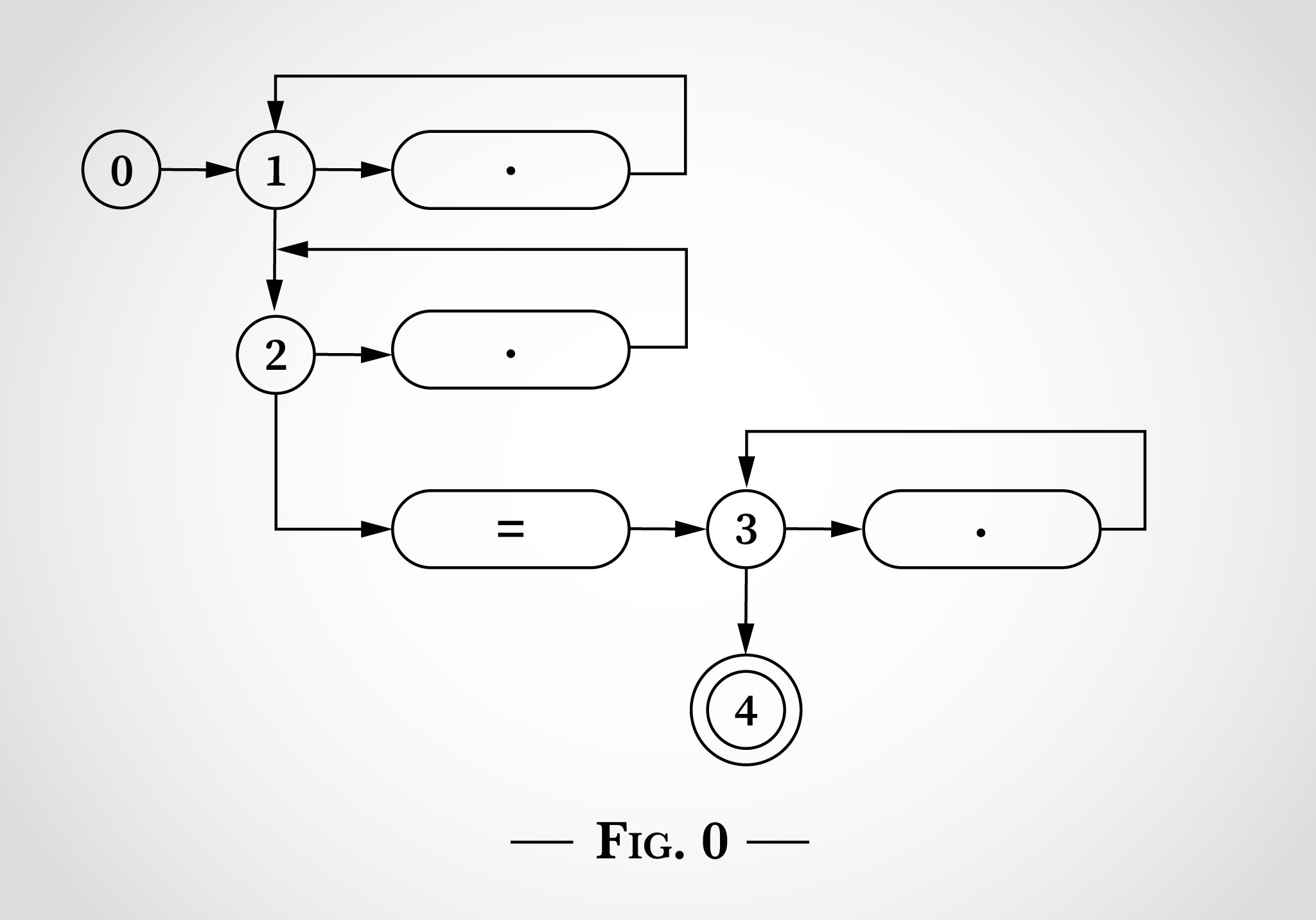
图 0,有五个从 0 开始的状态。有三个以状态1,2和3开始的循环。这三个循环对应于正则表达式中的三个.*。 带有圆点的三个椭圆片分别匹配了一个字符。带有=符号的椭圆片与=符号相匹配。状态 4 是结束状态,如果到达这里,则表示正则表达式已经完成匹配。
要查看这样的如何用于匹配.*.*=.*正则表达式的状态图,我们用x=x的字符串来检查匹配。 程序从状态 0 开始,如 图1 所示。
该算法工作的关键是使状态机同时处于多个状态。NFA 将同时进行能够操作的每次转换。
即使在读取任何输入之前,它也会立即转换到状态 1 和 2,如图2所示。
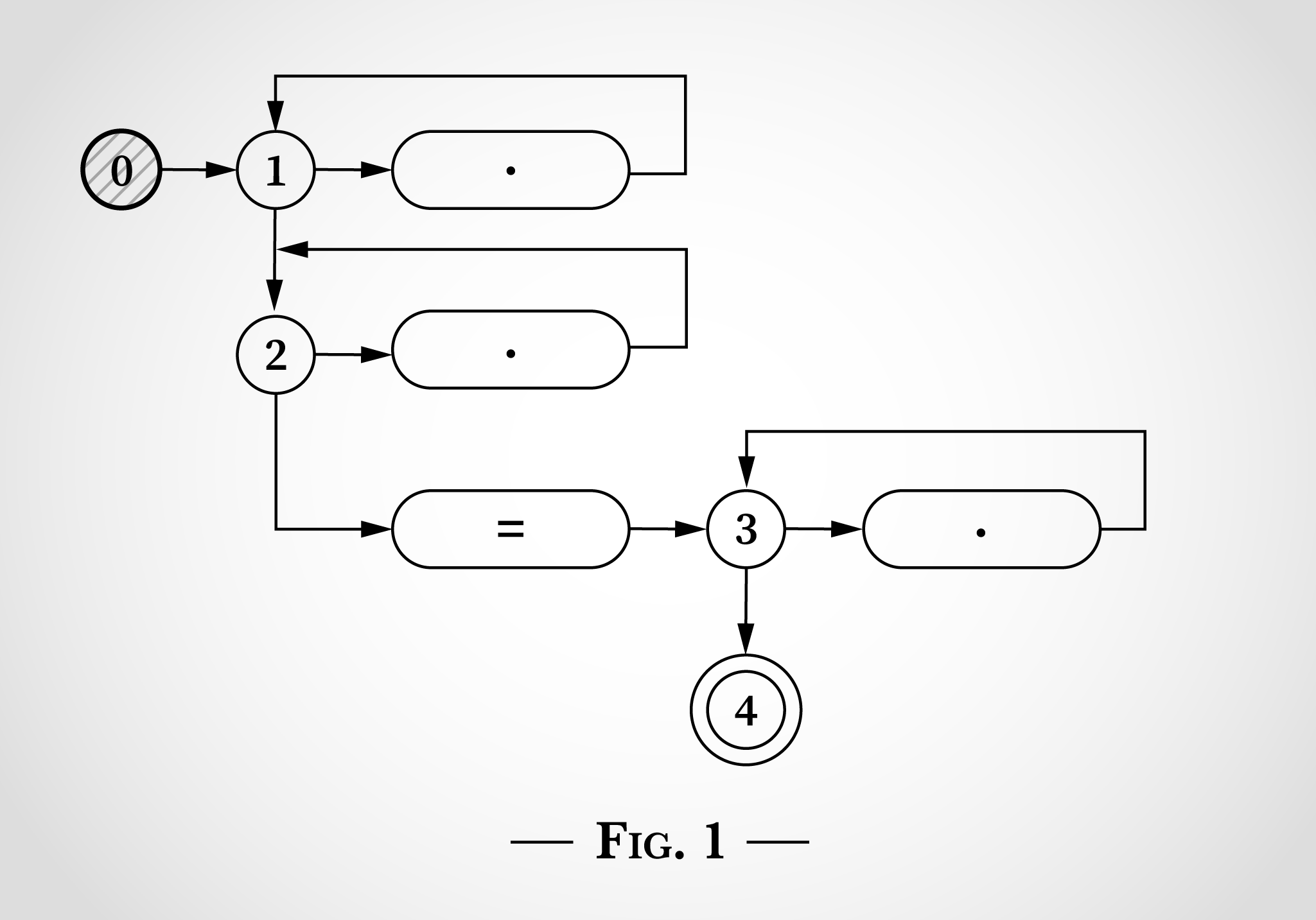
看 图2,我们可以看到当它在x=x中考虑匹配第一个x时发生了什么。x可以通过从 状态1 转换回 状态1 来匹配。或者x可以通过从下面的状态2转换回状态2来匹配表达式中的点。
因此,在匹配x=x中的第一个x之后,状态仍然处于 1和2 的位置。由于需要=符号,所以不可能达到状态 3 或 4。
接下来,算法考虑x=x中的=。与之前的x非常相似,它可以通过从 状态1 转换回 状态1,或 状态2 转换回 状态2,这两个循环中的任何一个匹配,另外=可以匹配,算法可以从 状态2 转换到 状态3(然后立即到达状态4)。 如图3所示。
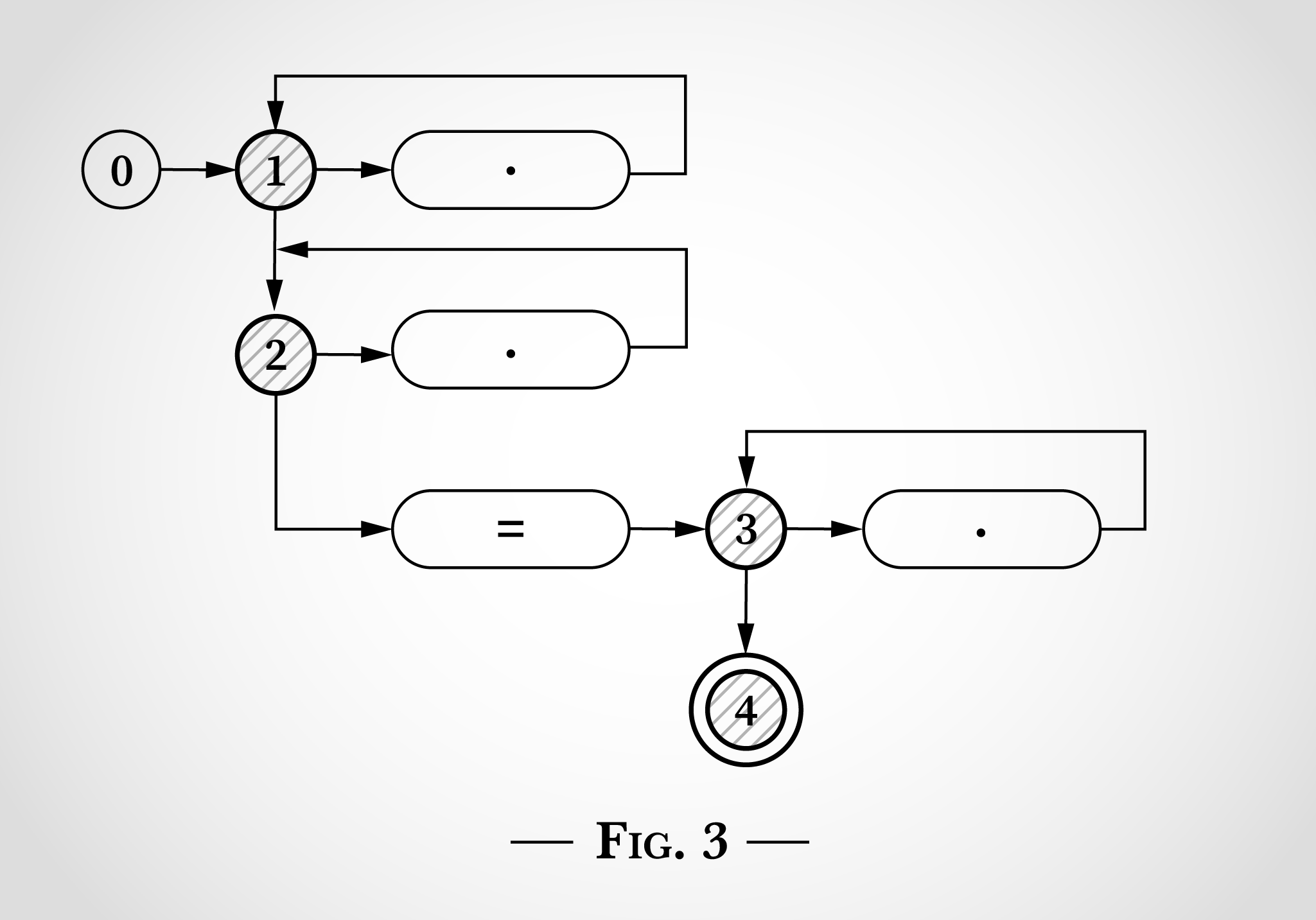
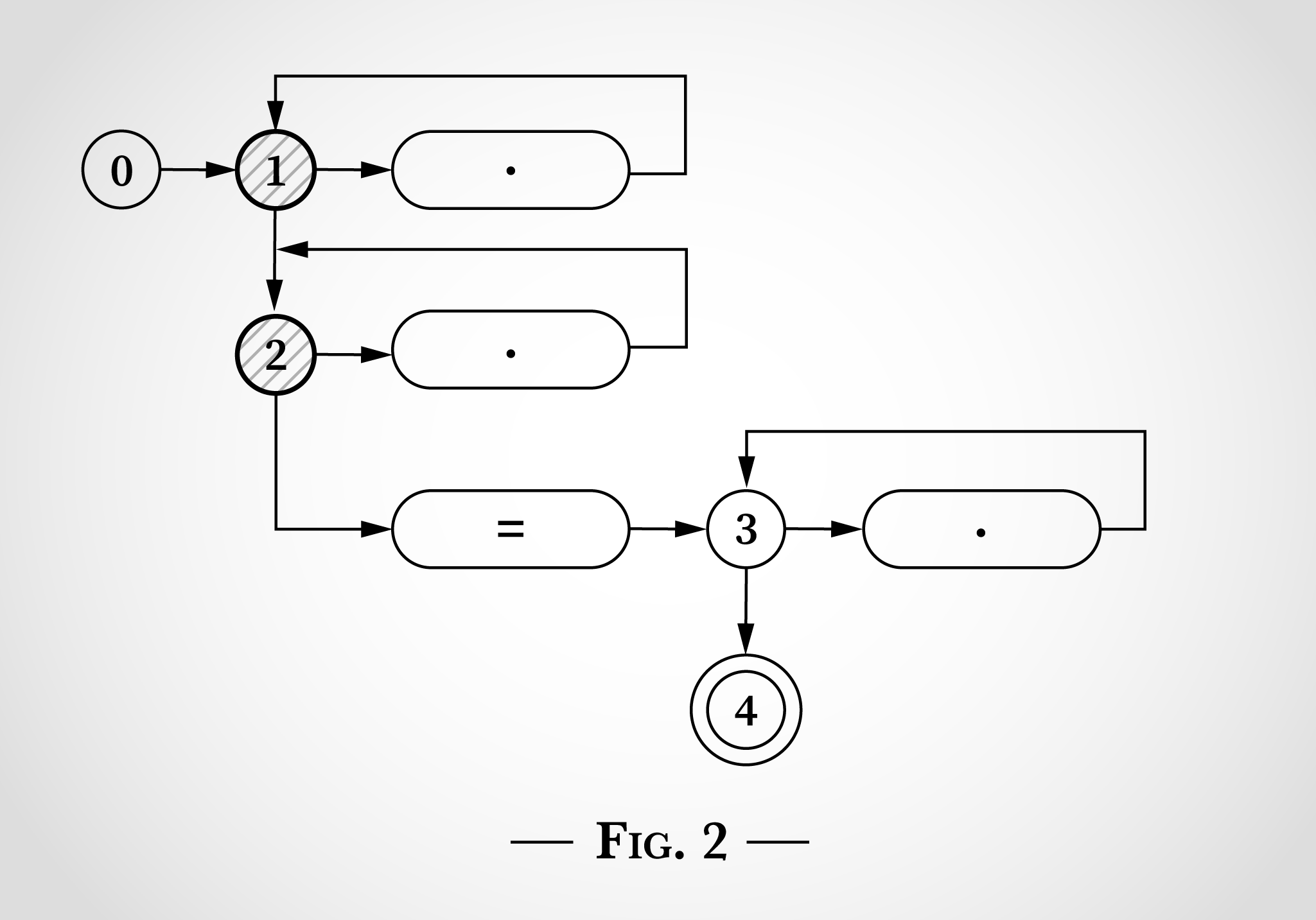
接下来,算法到达x=x中最后一个x。从状态1和状态2开始,相同的转换可以返回到状态1和2。从状态3开始,x可以匹配右边的点并转换回状态3。
此时,已经考虑了x=x的每个字符,并且因为已经到达状态4,所以正则表达式匹配了该字符串。每个字符仅被处理一次,因此算法在输入字符串的长度上是线性的。并且不需要回溯。
也许可能很明显,一旦达到状态4(在x=被匹配之后),正则表达式已经可以匹配,算法完全可以在不考虑最后一个x的情况下终止。
结果证明,该算法的输入大小是呈线性的。