
原文地址:https://blog.cloudflare.com/getting-to-the-core/
原文标题:Getting to the Core: Benchmarking Cloudflare’s Latest Server Hardware
原文作者:Brian Bassett
原文写于:2020/11/20
译者:驱蚊器喵#ΦωΦ
翻译水平有限,有不通顺的语句,请见谅。
维护像 Cloudflare 这样规模的服务器集群,可以说是操作上的挑战。为了降低复杂性和提高效率,我们所做的任何事情都会对我们的 SRE(Site Reliability Engineer,网站可靠性工程师)团队和数据中心团队造成影响,我们可以在4年多以来服务器的使用过程中感受到这些影响。
在 Cloudflare 的内部核心,我们处理日志用于分析攻击和计算分析数据。在2020年,我们的核心服务器需要更新,因此我们决定重新设计硬件,使其更符合我们的第十代边缘服务器。我们为核心设计了两个主要的服务器型号。第一个是 Core Compute 2020,这是一款基于 AMD 的服务器,用于分析和通用计算,搭配固态存储驱动器。第二个是 Core Storage 2020,这是一款基于 Intel 的服务器,配有 12 个机械磁盘,用于运行数据库相关的工作。
Core Compute 2020
今年早些时候,我们在博客中介绍了我们的第十代边缘服务器,以及它们在性能和安全方面为我们的边缘服务带来的改进。新的 Core Compute 2020 服务器利用了我们从边缘服务器中学到的许多知识。核心计算服务器运行各种工作负载,包括 Kubernetes、Kafka 和各种小型服务。
配置更改 (Kubernetes)
| 上一代 | Core Compute 2020 | |
|---|---|---|
| CPU | 2 x Intel Xeon Gold 6262 | 1 x AMD EPYC 7642 |
| 核心数 / 线程数 | 48C / 96T | 48C / 96T |
| 基础 / 超频的频率 | 1.9 / 3.6 GHz | 2.3 / 3.3 GHz |
| 内存 | 8 x 32GB DDR4-2666 | 8 x 32GB DDR4-2933 |
| 存储 | 6 x 480GB SATA SSD | 2 x 3.84TB NVMe SSD |
| 网络 | Mellanox CX4 Lx 2 x 25GbE | Mellanox CX4 Lx 2 x 25GbE |
配置更改 (Kafka)
| 上一代 (Kafka) | Core Compute 2020 | |
|---|---|---|
| CPU | 2 x Intel Xeon Silver 4116 | 1 x AMD EPYC 7642 |
| 核心数 / 线程数 | 24C / 48T | 48C / 96T |
| 基础 / 超频的频率 | 2.1 / 3.0 GHz | 2.3 / 3.3 GHz |
| 内存 | 6 x 32GB DDR4-2400 | 8 x 32GB DDR4-2933 |
| 存储 | 12 x 1.92TB SATA SSD | 10 x 3.84TB NVMe SSD |
| 网络 | Mellanox CX4 Lx 2 x 25GbE | Mellanox CX4 Lx 2 x 25GbE |
Kubernetes 服务器基于 Xeon 6262 处理器,而 Kafka 服务器基于 Xeon 4116 处理器,上一代的两种服务器都是基于 Intel 平台,这些更新版本的一个目标是融合配置,以简化整个集群的备件和固件管理。
如上表所示,这些配置已经融合,唯一的区别是根据主机上运行的工作负载不同,而安装的 NVMe 驱动器数量。在这两种情况下,我们从双插槽配置转为单插槽配置,每台服务器的核心和线程数量要么增加,要么保持不变。在所有情况下,这些核心的基本频率都有明显的提高。我们还从 SATA 固态硬盘迁移到了 NVMe 固态硬盘。
Core Compute 2020 的合成基准测试
Kafka 是 SSD 的重度用户。大部分时间 Kafka 都是按顺序向磁盘写入大小 2MB 的块。我们创建了一个简单的 FIO 脚本,其中有 75% 的顺序写入和 25% 的顺序读取,将块的大小从标准的页表条目大小 4096B 扩展到 Kafka 的 2MB 写入大小。结果与我们对基于 NVMe 的驱动器的预期一致。
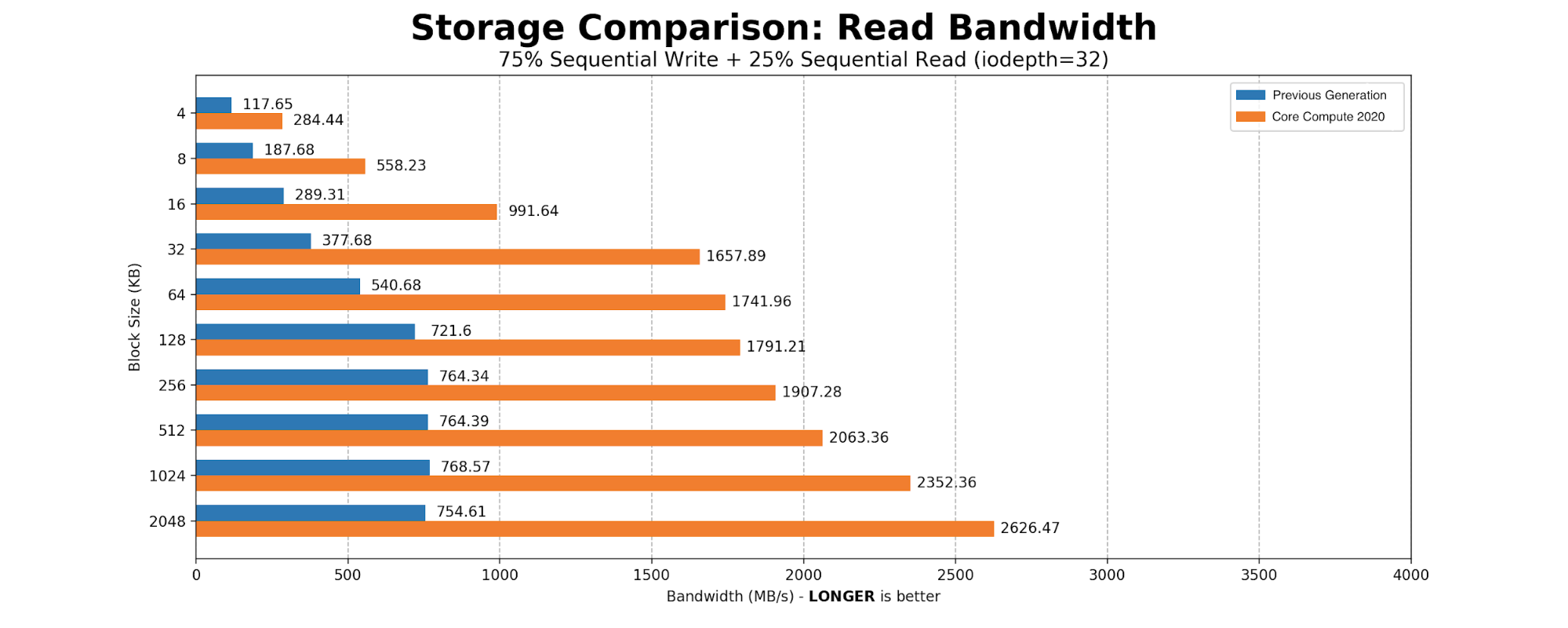
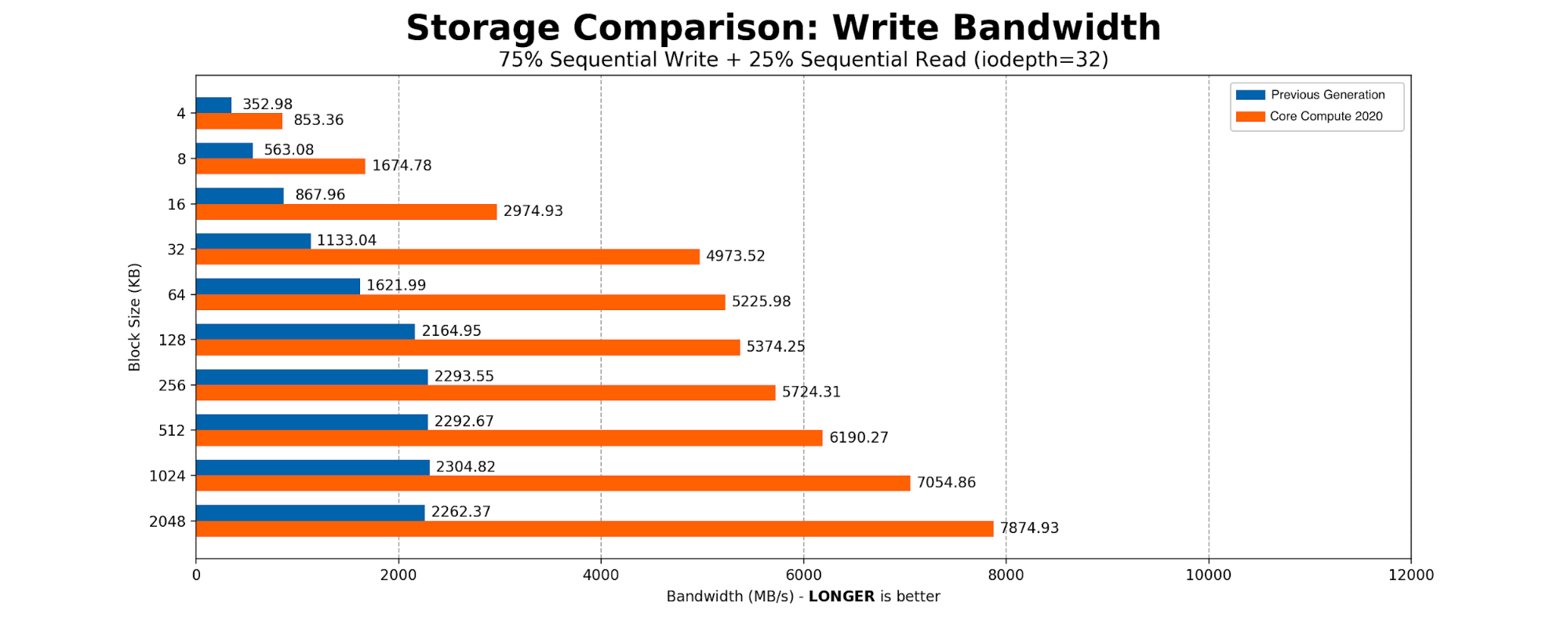
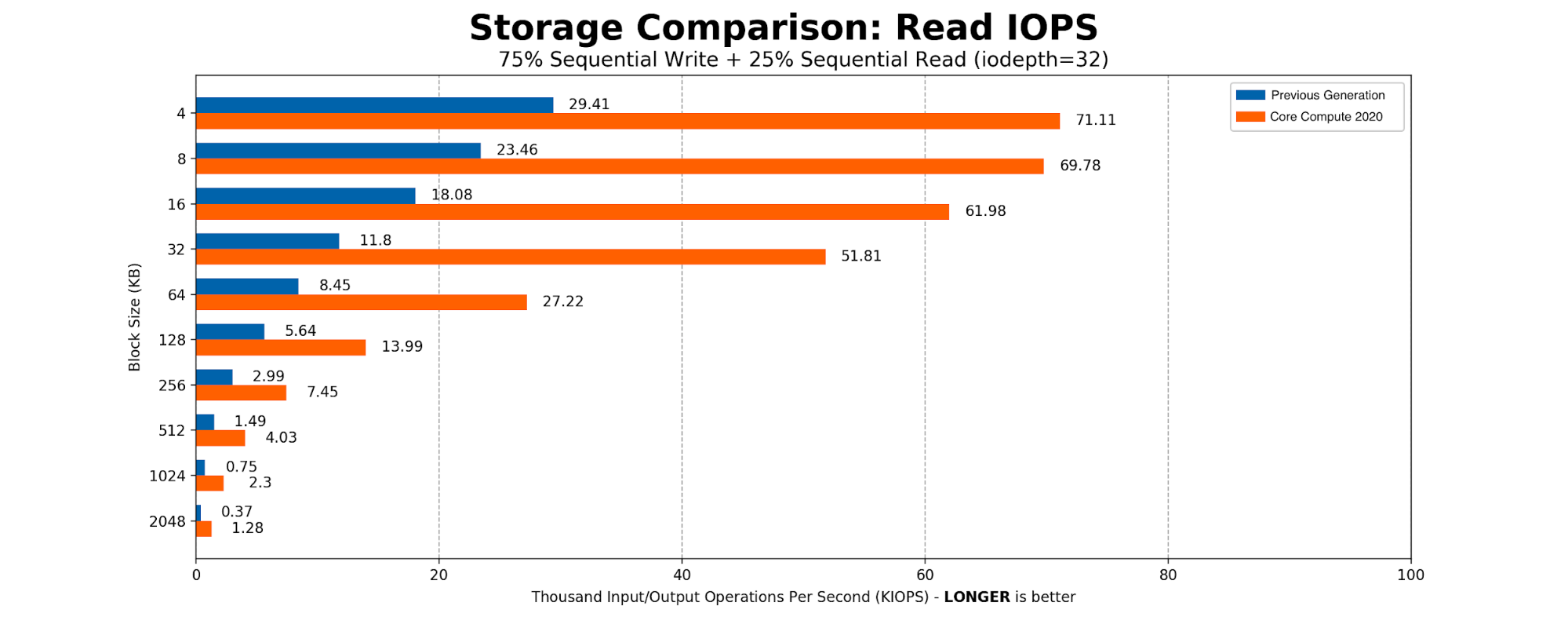
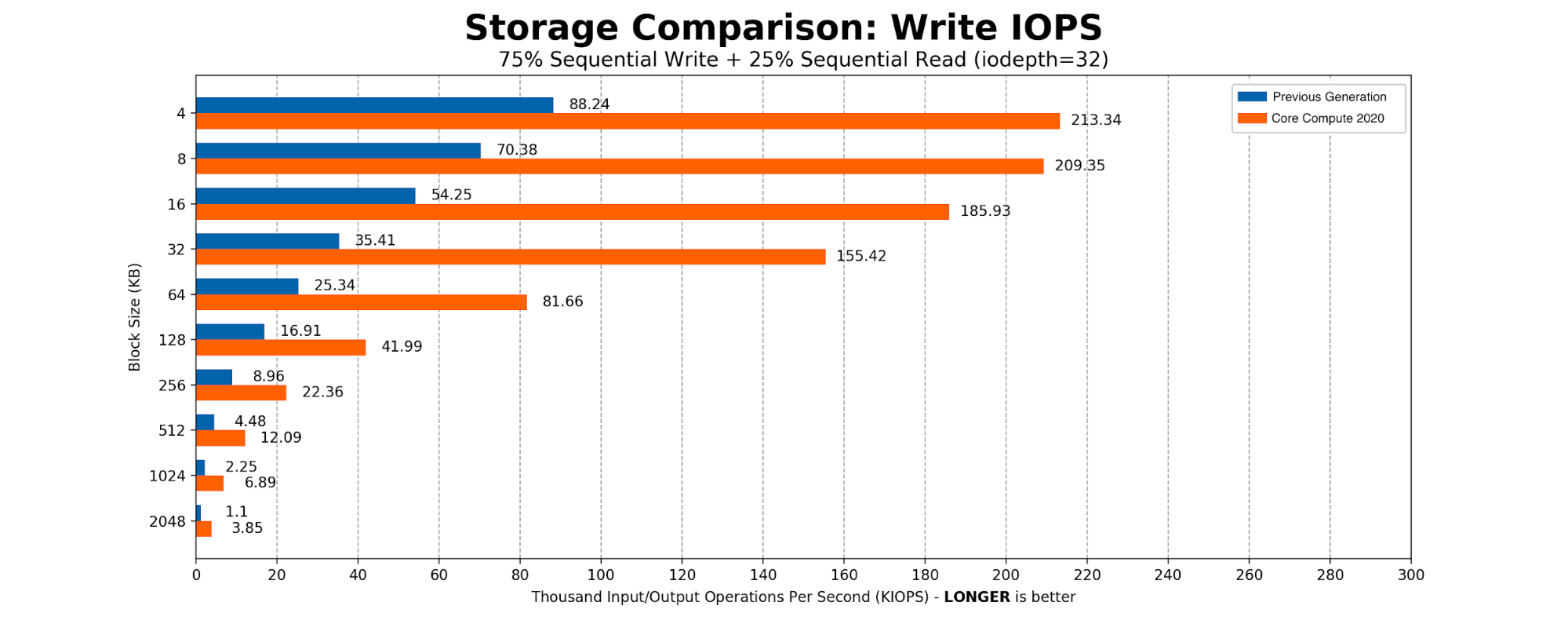
Core Compute 2020 的生产环境基准测试
Cloudflare 的 Kubernetes 容器中运行许多核心计算服务,其中一些计算任务是多核的。通过过渡到单套接字,消除了与双套接字相关的问题,我们保证在同一套接字上为任何特定的容器分配所有核心。
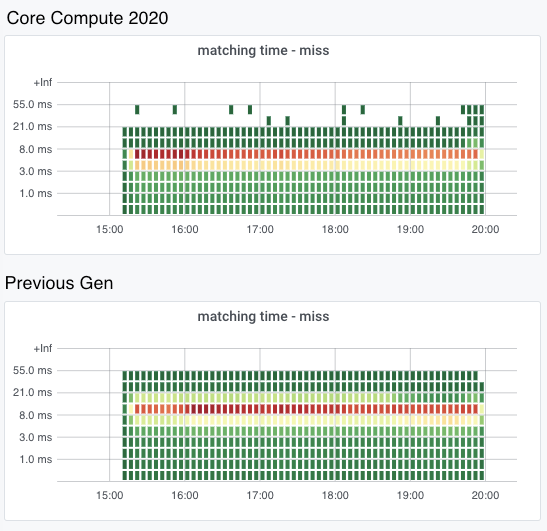
另一个在计算主机上一直运行的繁重工作任务是 CSAM 扫描工具。我们的系统工程团队隔离了一台 Compute 2020 计算主机和上一代的计算主机,让它们只运行这个工作任务,并测量了将图像的模糊哈希值与 NCMEC 哈希列表进行比较的时间,并验证它们是一个”未命中”的图像。
由于 CSAM 扫描工具是计算非常密集的工具,我们特别把它隔离出来,看看它在新硬件上的性能。我们已经在软件优化和改进工具的算法方面花费了大量精力,但投资于更快、更好的硬件同样很重要。
在这些热力图中,X 轴代表时间,Y 轴代表验证是否与 NCMEC 的哈希列表之一相匹配所花费的时间的”桶”。对于热图中的某个时间片,红点是测量时间最多的桶,黄点是第二多,绿点是最少。Compute 2020 图上的红点都在 5-8 毫秒的桶里,而上一代计算机的热图上,红点都在 8-13 毫秒的桶里,这表明平均而言,Compute 2020 主机验证哈希值的速度明显加快。
Core Storage 2020
我们确定的另一个主要工作任务是 ClickHouse ,用于对大型数据集进行分析。我们上次升级运行ClickHouse 的服务器是在 2018 年。
配置更改
| 上一代服务器 | Core Storage 2020 | |
|---|---|---|
| CPU | 2 x Intel Xeon E5-2630 v4 | 1 x Intel Xeon Gold 6210U |
| 总核心数 / 线程数 | 20C / 40T | 20C / 40T |
| 基本频率 / 涡轮增压频率 | 2.2 / 3.1 GHz | 2.5 / 3.9 GHz |
| 内存 | 8 x 32GB DDR4-2400 | 8 x 32GB DDR4-2933 |
| 存储 | 12 x 10TB 7200 RPM 3.5” SATA | 12 x 10TB 7200 RPM 3.5” SATA |
| 网络 | Mellanox CX4 Lx 2 x 25GbE | Mellanox CX4 Lx 2 x 25GbE |
CPU 更改
对于 ClickHouse,我们使用一个1U的机箱,有 12 个 10 TB 的 3.5 英寸硬盘。在我们设计 Core Storage 2020 的时候,我们的服务器供应商还没有这种机箱的 AMD 版本,所以我们仍然使用英特尔。然而,我们将 Core Storage 2020 转移到一个单一的20核/40线程的 Xeon处理器,替换了上一代的双插槽10核/20线程处理器。通过转移到单插槽 Xeon 6210U 处理器,我们能够保持在相同的核心数量下,获得17%的基本频率和26%的最大涡轮增压频率提升。同时,总的 CPU 热设计曲线(TDP,thermal design profile),也就是 CPU 可以吸取的最大功率的近似值,从 165W 下降到了 150W。
在双插槽服务器上,远程内存访问,由插槽0上的进程对连接到插槽1上的内存进行的内存访问,会产生延迟惩罚(latency penalty),如下表所示。
| 上一代计算机 | Core Storage 2020 | |
|---|---|---|
| 从0插槽到0插槽的内存延迟 | 81.3 ns | 86.9 ns |
| 从0插槽到1插槽的内存延迟 | 142.6 ns | N/A |
将所有20个内核放在同一个插槽上的CPU的另一个好处是消除了这些远程内存访问,这些访问比本地内存访问的时间要长76%。
内存更改
Core Storage 2020 主机内存的额定运行频率为 2933 MHz;然而,在我们在这些主机上需要的 8 x 32GB 配置中,英特尔 Xeon 6210U 处理器将它们的时钟设定为 2666 MH。与上一代产品相比,这使我们的内存速度提升了 13%。虽然我们可以通过平衡的 6 个 DIMMs 配置获得稍高的时钟速度,但我们仍然决定,我们愿意牺牲稍高的时钟速度,以获得 8 x 32GB 配置所提供的额外内存容量。
存储更改
数据容量保持不变,有 12 个 10 TB 的 SATA 硬盘,采用 RAID 0 配置,以获得最佳吞吐量。与上一代不同,Core Storage 2020 主机中的硬盘是氦气填充的。氦气产生的阻力比空气小,从而降低延时。
Core Storage 2020 合成基准测试
我们进行了合成四角基准测试。使用 4k 块大小的随机读写的 IOPS 测量,以及使用 128k 块大小的顺序读写的带宽测量。我们使用 fio 工具来看看我们在实验室环境中会得到什么改进。结果显示,在随机读取性能方面,延迟提高了10%,IOPS 提高了11%。随机写入测试显示延迟降低了38%,IOPS 提高了60%。写入吞吐量提高了23%,读取吞吐量提高了惊人的90%。
| 上一代服务器 | Core Storage 2020 | % Improvement | |
|---|---|---|---|
| 4k 随机读取 (IOPS) | 3,384 | 3,758 | 11.0% |
| 4k 随机读取平均延迟 (ms, 越低越好) | 75.4 | 67.8 | 10.1% lower |
| 4k 随机写入 (IOPS) | 4,009 | 6,397 | 59.6% |
| 4k 随机写入平均延迟 (ms, 越低越好) | 63.5 | 39.7 | 37.5% lower |
| 128k 顺序读取 (MB/s) | 1,155 | 2,195 | 90.0% |
| 128k 顺序写入 (MB/s) | 1,265 | 1,558 | 23.2% |
CPU 频率
Core Storage 2020 主机的 Xeon 6210U 处理器的基础频率和涡轮增压频率较高,这使得该处理器在运行 ClickHouse 工作负载时能达到更高的平均频率。最近,两个生产主机的快照显示,Core Storage 2020 主机在运行 ClickHouse 时,能够维持平均 31% 更高的 CPU 频率。
| 上一代 (平均核心频率) | Core Storage 2020 (平均核心频率) | 提升的百分比 | |
|---|---|---|---|
| Mean Core Frequency | 2441 MHz | 3199 MHz | 31% |
Core Storage 2020 生产环境测试
我们的 ClickHouse 数据库主机不断地进行合并操作,来优化数据库的数据结构。每个单独的合并操作平均只需要几秒钟,但由于它们一直在运行,所以会消耗主机上的大量资源。我们在七天内每五分钟抽查一次平均合并时间,然后对数据进行抽查,找出 Compute 2020 主机和上一代主机报告的平均、最小和最大合并时间。结果总结如下。
ClickHouse 合并操作性能提高(时间以秒为单位,越低越好)
| 时间 | 上一代计算机 | Core Storage 2020 | % 提升 |
|---|---|---|---|
| 合并的平均时间 | 1.83 | 1.15 | 37% lower |
| 合并的最长时间 | 3.51 | 2.35 | 33% lower |
| 合并的最短时间 | 0.68 | 0.32 | 53% lower |
我们在实验室测量的 Core Storage 2020 的 CPU 频率和存储性能的改进,转化为大大减少执行数据库操作的时间。
总结
通过 Core 2020 服务器,我们能够实现显著的性能改进,无论是在生产以外的合成基准测试还是在我们测试的生产工作负载中。这将使 Cloudflare 能够在更少的服务器上运行相同的工作负载,节省资本支出成本和数据中心机架空间。Kubernetes 和 Kafka 主机配置的相似性应该有助于集群管理和备件管理。对于我们的下一次重新设计,我们将尝试进一步融合我们运行主要核心工作负载的设计,以进一步提高效率。