
原文地址:https://blog.cloudflare.com/clickhouse-capacity-estimation-framework/
原文标题:ClickHouse Capacity Estimation Framework
原文作者:Oxana Kharitonova
原文写于:2020/11/05
译者:驱蚊器喵#ΦωΦ
翻译水平有限,有不通顺的语句,请见谅。
在 Cloudflare,我们广泛使用 ClickHouse 。ClickHouse 支撑着我们的内部分析工作负载,机器人管理,客户仪表盘和许多其他系统。例如,我们需要收集日志,以供 僵尸管理(Bot Management)功能 分析和分类我们的流量。防火墙分析(Firewall Analytics) 工具也需要存储和查询数据。我们的新项目,Cloudflare Radar project ,也是如此。我们正在使用 ClickHouse 来实现这一目的。ClickHouse 是一个巨大的数据库,可以存储海量数据并按需返回。这不是我们第一次谈到 ClickHouse,我们有一篇专门的文章介绍了我们如何使用 ClickHouse 进行 HTTP 分析。
我们最大的 ClickHouse 集群有 100 多个节点,另外一个集群大概有 50 多个节点。除此之外,我们有 20 多个集群,每个集群至少有 3 个节点,以及 3 个复制副本。目前,我们的插入速率大概是每秒 9000 万行。
在 ClickHouse 模式设计中,我们使用标准的方法。在顶层,我们有集群,里面有分片,有一组节点,一个节点就是一台物理机。你可以在这里找到节点的相关技术特征。存储的数据在集群之间进行复制。不同的分片保存着不同部分的数据,但是在每个分片里面复制的数据是相同的。
一个集群的设计模式如下:

容量规划
作为工程师,我们周期性地面临这样一个问题,即我们必须增加多少个节点才能支持未来 X 个月不断增长的需求,磁盘空间是我们最关心的问题。
ClickHouse 在系统表中存储了大量关于操作进程的信息,这对分析很有帮助。从使用 ClickHouse 的早期,我们就添加了 clickhouse_exporter 作为我们监控栈的一部分。我们感兴趣的一个指标是从 system.parts 表中找到的。大致来说,clickhouse_exporter 运行 SQL 查询,查询每个表使用了多少字节。之后,这些指标会被 Prometheus 发送到 Thanos,并存储至少一年。
每次我们想对磁盘使用情况进行预测时,我们都会用这个表达式向 Thanos 查询历史数据。
1 | sum by (table) (sum(table_parts_bytes{cluster="{cluster}"})) |
之后,我们将数据以 dataframes 的形式上传到 Jupyter notebook 上。
这种方法有几个问题。只有少数人知道 notebook 的位置,以及如何让它们运行。下载历史数据并不容易。最重要的是,很难查看过去的预测并评估它们是否正确,因为除了内部博客文章之外,查询结果没有存储在其他地方。此外,随着集群和产品的数量和规模增长,对于一个团队而言,从事容量规划工作是一件不可能的事情,我们需要让构建产品的工程师参与进来,因为他们对未来的增长变化有最多的发言权。
我们希望将这一过程自动化,并让我们的同事,包括那些使用 ClickHouse 服务的人,了解计算结果。说实话,一开始我们并不确定这是否可能,也不知道我们会从中得到什么。
寻找最佳指标
对我们来说,添加新节点的关键问题是磁盘空间,所以这是开始的地方。我们决定使用 system.part,因为我们之前用的是手动方式。
幸运的是,我们开始为最近改变了拓扑结构的集群做这件事。那个集群有两个分片,一个分片里有四个节点,另一个分片里面是五个节点。在拓扑结构改变后,每个分片中有三个节点,机器数量和磁盘上的未复制数据保持不变。但是,这对我们的指标产生了影响:我们之前在一个分片中有4个复制节点,在另一个分片中有5个复制节点,我们从第一个分片中去掉了一个节点,从第二个分片中去掉了两个节点,并基于这三个节点创建了一个新的分片。新的分片是空的,所以我们就把它加上去,但是第一个和第二个分片中的数据总量是减少的,因为节点数量也是减少了。
你可以在下面的图上看到,在4月份,由于拓扑变化,我们的分片空间急剧下降。我们所有分片和副本中的空间大小是 550T 而不是 850T。
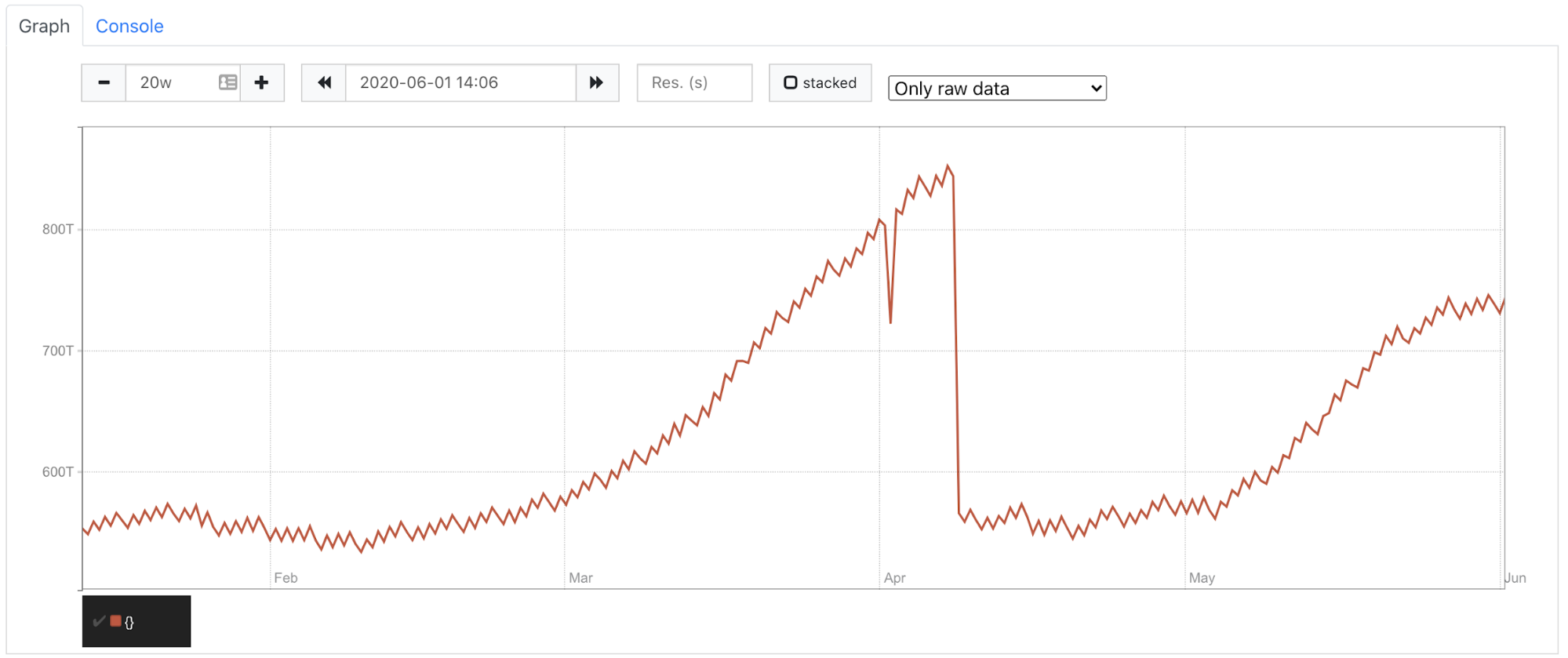
当我们试图根据真实数据训练我们的模型时,由于4月份的空间下降,模型认为我们有一个下降的趋势。这是不正确的,因为我们只丢弃了复制的数据。未复制数据的趋势并没有改变。所以我们决定只考虑未复制的数据。这让我们省去了在硬件出现问题时的拓扑变化和节点更换。
我们现在用于衡量指标的规则是:
1 | sum by(cluster) ( |
我们继续使用 clickhouse_exporter 中的 system.part ,但我们不是计算整个数据量,而是使用每个分片中未复制数据的最大值。
在下图中,有和上图一样的集群,但我们不是计算整个数据量,而是看所有分片的未复制数据。你可以清楚地看到,我们的数据量继续增长,没有看到任何数据下降的情况。
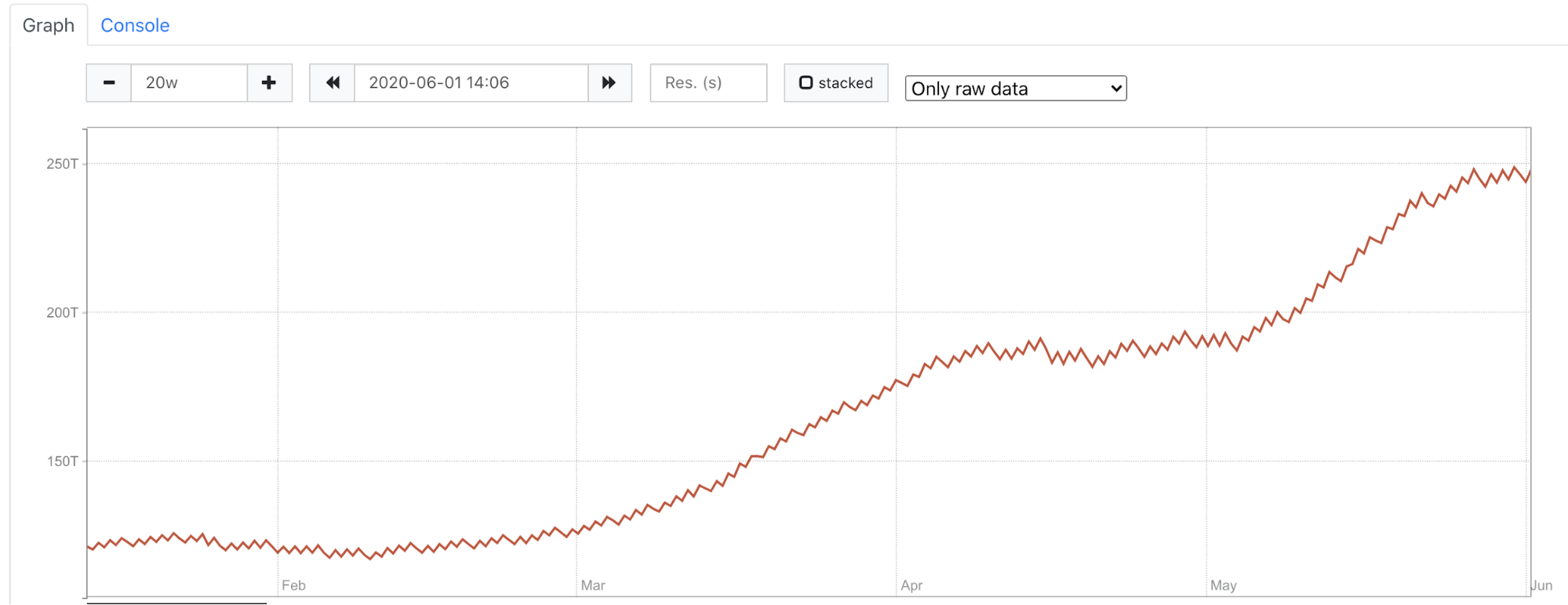
我们面临的另一个问题是,我们将一些表从一个集群迁移到另一个集群,因为我们的空间已经用完了,需要立即采取行动。然而,我们的模型不知道这部分表已经不在那里了,我们不希望它们成为预测的一部分。为了解决这个问题,我们查询 Prometheus 获取到预测时所有的数据表,然后过滤历史数据,使预测时只包括这些表,并将它们作为训练模型的输入。
加载指标
在确定了正确的指标之后,我们需要为我们的预测程序获取这些指标。我们的 Thanos 存储了数十亿的数据点。对一个超过一百个节点的集群进行查询,即使是一天也需要大量的时间,而我们需要这些一年的数据点。
我们计划使用 Python,所以我们用aiohttp写了一个小巧的客户端,向 Thanos 并发发送 HTTP 请求。这些请求是分块发送的,每个请求的开始/结束日期都有一个小时的差异。我们需要一次性获取全年的数据,然后逐日追加新的数据。我们得到了 csv 文件:一个文件对应一个集群。这个 Python 客户端成为项目的一部分,每天运行一次,查询 Thanos 的新指标(前一天),并将数据追加到文件中。
预测程序
此时,我们已经收集了文件中的指标,现在是时候做一个预测了。我们需要一些时间序列指标的东西,所以我们选择了 Facebook 的Prophet。它的使用非常简单,你可以按照文档进行操作,即使使用默认参数也能得到很好的结果。
我们在使用 Prophet 时面临的一个挑战是,需要给 Prophet 提供一天的一个数据点。在指标文件中,我们每天都有成千上万个这样的数据。在每天结束时取点看起来很合理,但实际上并不是这样。所有的表都有一个保留期,即我们在 ClickHouse 中存储数据的时间。我们不知道数据什么时候被清除,因为清除发生在一天中的每时每刻。所以,我们决定取一天的最大量。
展示结果
我们选择了 Grafana 来展示结果,不过我们需要在某个地方存储预测的数据点。最初的想法是使用 Prometheus,但基数很高(high cardinality,意思是说唯一值很多),因为我们有大约 30 万个点的集群和数据表的指标数据,所以我们否决了这个方案。最后,我们决定使用 ClickHouse 本身。我们希望在同一个仪表盘上有真实和预测的两种图。我们在 Prometheus 中有真实的数据点,并且有混合数据源这个功能可以做到这一点。但是,问题和将指标加载到文件中一样,对于一些集群来说,长时间无法获得指标。我们在 ClickHouse 中也增加了上传真实指标的功能,现在 Grafana 中同时显示真实的指标和预测的指标,都取自于 ClickHouse。
总结
这就是我们在 Grafana 的情况。
- 黄线:是真实数据
- 绿线:根据 Prophet 的输出创建
- 红线:最大磁盘容量。我们已经增加了两次。
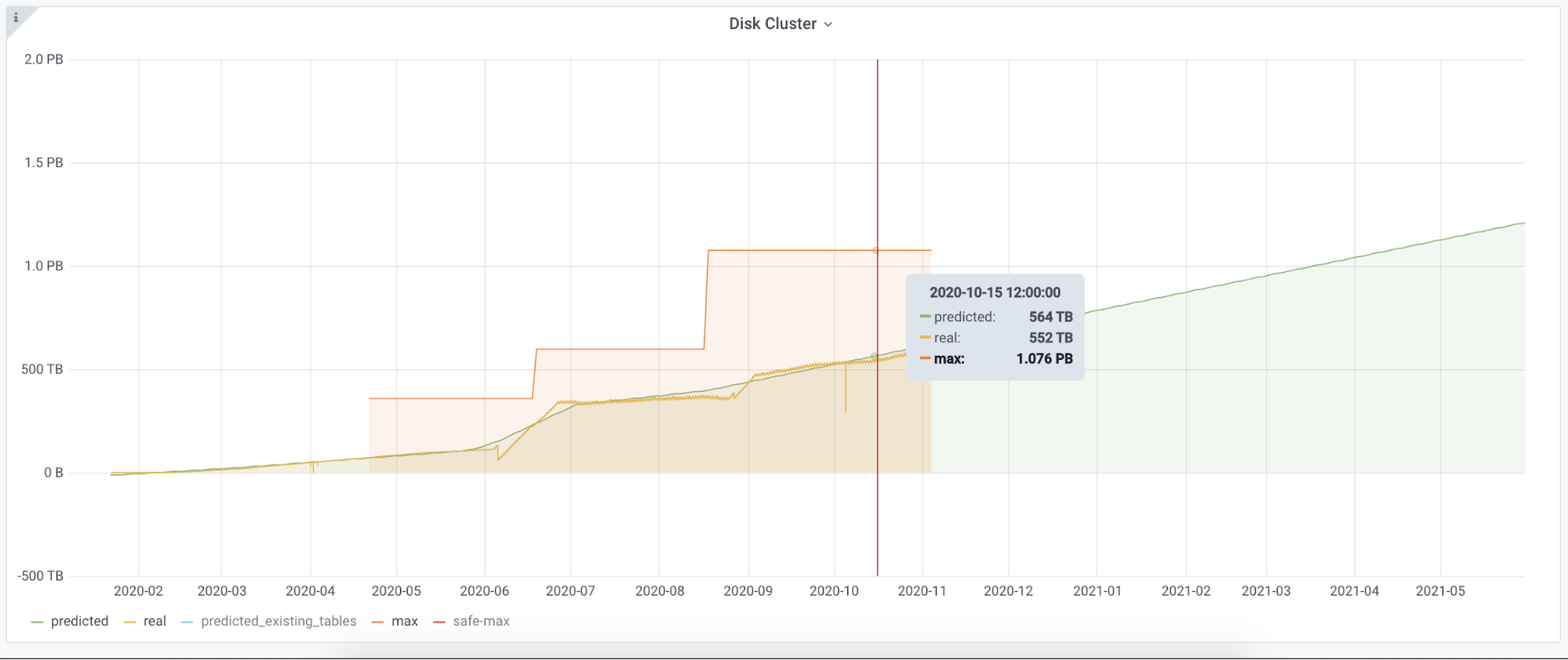
我们有一个运行在 Kubernetes 中的服务,完成了所有的工作,我们为其他的指标创建了一个环境。我们有一个地方,我们从 Thanos 收集指标,并以所需的格式暴露给 Grafana。如果我们找到合适的指标来核算其他资源,比如 IO、CPU 或其他系统,比如 Kafka,我们可以很容易地把它们添加到我们的框架中。我们可以很容易地用另一种算法替换 Prophet,我们可以回到几个月前,评估我们的预测数据离真实数据的距离有多远。
通过这种自动化,我们发现我们有几个集群的磁盘空间要用完了,这是我们没有想到的。我们有20多个集群,每天都会对所有集群进行更新。这个仪表盘不仅被我们的同事,ClickHouse 的直接用户使用,也提供给负责做服务器购买计划的团队使用。图表容易阅读,并且不会消耗开发人员的时间。
这个项目是由核心 SRE 团队进行的,用于改善我们的日常工作效率。