
原文地址:https://blog.cloudflare.com/http-analytics-for-6m-requests-per-second-using-clickhouse/
原文标题:HTTP Analytics for 6M requests per second using ClickHouse
原文作者:Marek Vavruša
原文写于:2017/03/07
译者:驱蚊器喵#ΦωΦ
翻译水平有限,有不通顺的语句,请见谅。
在 Cloudflare,我们的大规模数据基础设施的一个挑战是为我们的客户提供 HTTP 流量分析。我们所有客户都可以通过两种方式使用 HTTP 分析功能:
- Cloudflare 面板里面的 Analytics 选项
- Zone Analytics API 中的 2 个端点
- Dashboard endpoint
- Co-locations endpoint ( 仅 Enterprise 套餐)
在这篇博文中,我将谈谈 Cloudflare 分析管道在过去一年中的精彩变革。首先,我将描述之前的管道和我们所经历的挑战。然后,我会介绍我们如何利用 ClickHouse 形成新的和改进后的管道的基础组件。在这个过程中,我将分享我们如何去为 ClickHouse 进行的模式设计以及性能调优的细节。最后,我会展望数据团队未来将要提供的想法。
我们先从之前的数据管道说起。
之前的数据管道
之前的数据管道建立于 2014 年。之前在数据团队写的两篇文章 使用 CitusD 为 CloudFlare 分析的 PostgreSQL 扩容 和 越来越多的数据 中提到过。
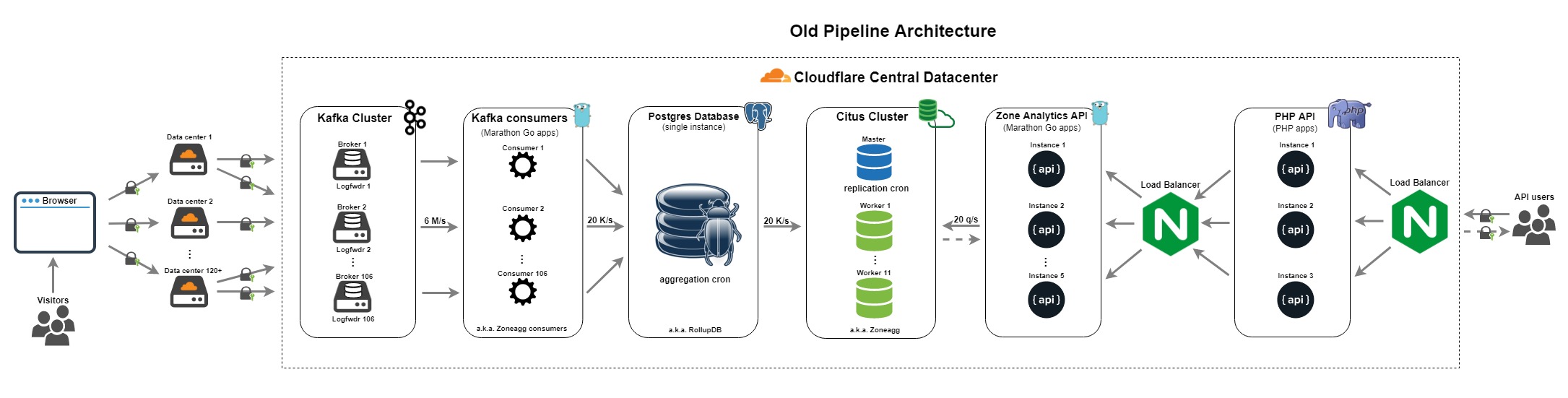
数据管道有以下组成部分:
日志转发器 - 从边缘服务器收集 Cap’n Proto 格式的日志,特别是 DNS 和 Nginx 日志,并将其传送到 Cloudflare 中央数据中心的 Kafka。
Kafka 集群 - 由 106 个 broker 组成,3 复制副本,106 个分区,以平均每秒 6M 日志的速度摄取 Cap’n Proto 格式的日志。
Kafka 消费者 - 106 个分区中的每个分区都有专门的 Go 消费者(又名 Zoneagg 消费者),它每分钟读取日志并按每个分区每域产生汇总,然后写入 Postgres。
Postgres 数据库 - 单实例 PostgreSQL 数据库(又名 RollupDB ),接受 Zoneagg 消费者的汇总数据,按每分钟每域将其写入到临时表。然后,用聚合 cron 将这些聚合数据上卷(roll-up)成更进一步的聚合。具体的细节如下:
- 按分区、分钟、域 汇总 → 按分钟、域 汇总
- 按分钟、域 汇总→ 按小时、域 汇总
- 按小时、域 汇总 → 按天、域 汇总
- 按天、域 汇总 → 按月、域 汇总
Citus 集群 - 由 Citus 主服务和 11 个 Citus worker 组成,2 复制副本(也就是 Zoneagg Citus 集群),是 Zone Analytics API 以及我们内部 BI 工具背后的存储。它有复制cron,可以将 Postgres 实例中的表远程复制到 Citus worker shards 中。
Zone Analytics API - 从内部 PHP API 中提供查询服务。由 5 个用 Go 编写的 API 实例组成,并对 Citus 集群进行查询,外部用户不可见。
PHP API - 3 个代理 API 的实例,将公共 API 查询转发到内部 Zone Analytics API,并有一些关于域计划、错误信息等的业务逻辑。
负载均衡器 - nginx 代理,将查询转发到 PHP API/Zone 分析 API。
自 2014 年最初设计这个管道以来,Cloudflare 已经有了巨大的发展。它一开始处理不到每秒 100 万的请求,发展到目前每秒 600 万请求的水平。多年来,该管道为我们和客户提供了很好的服务,但开始出现纹裂。任何系统,在运行在一段时间后,都应该在需求发生变化时重新设计。
原有管道的一些具体缺点是:
- Postgres SPOF - 单个 PostgreSQL 实例是一个 SPOF(单点故障),因为它没有副本或备份,如果我们失去了这个节点,整个分析管道可能会瘫痪,并且不会产生 Zone Analytics API 的新聚合。
- Citus main SPOF - Citus 主服务是所有 Zone Analytics API 查询的入口,如果它宕机了,我们所有客户的 Analytics API 查询都会返回错误。
- 复杂的代码库 - 用于聚合的 bash 和 SQL 代码有几千行,以及用于 API 和 Kafka 消费者的 Go 代码也有几千行,使得管道难以维护和调试。
- 过多的依赖性 - 管道由许多组件组成,任何单个组件的故障都可能导致整个管道停止运行。
- 高昂的维护成本–由于其复杂的架构和代码库,经常发生事故,有时需要数据团队和其他团队的工程师花费许多小时来缓解。
随着时间的推移,以及我们请求量的增长,维护这个数据管道的挑战变得更加明显,我们意识到这个系统的运行正在处于极限状态。这种认识启发我们思考,哪些组件是理想的替换对象,并促使我们建立新的数据管道。
我们第一次设计改进的分析管道,主要围绕着 Apache Flink 流处理系统的使用。我们以前曾在其他数据管道中使用过 Flink,所以它对我们来说是一个自然的选择。然而,这些管道的速率远远低于我们需要为 HTTP 分析处理的每秒 600 万个请求,我们努力让 Flink 扩展到这个数量 - 但是它仍然无法跟上每秒每分区一共 6M 个 HTTP 请求的的摄取速率。
我们 DNS 团队的同事已经在 ClickHouse 上建立并生产了 DNS 分析管道。他们在 “Cloudflare 如何每秒分析 1M DNS 查询“的一文中记录了过程。因此,我们决定对 ClickHouse 进行更深入的研究。
ClickHouse
“ClickHouse не тормозит.”
从俄罗斯翻译: ClickHouse 没有刹车(或速度不慢)。
© ClickHouse 核心开发者
“ClickHouse не тормозит.”
Translation from Russian: ClickHouse doesn’t have brakes (or isn’t slow)
© ClickHouse core developers
我们需要替换之前管道中的一些关键基础组件,在探索这些组件的候选方案时,我们意识到使用面向列的数据库可能非常适合我们的分析工作。我们希望找一个列式数据库,可以水平扩展和容错,以帮助我们提供良好的正常运行时间保证,并具有极高的性能和空间效率,从而可以处理我们这样规模的数据。我们很快意识到,ClickHouse 可以满足这些标准,而且还远不止此。
ClickHouse 是一个开源的列式数据库管理系统,能够使用 SQL 查询实时生成分析数据报表。它的速度超级快,可线性扩展,硬件高效,容错,功能丰富,高度可靠,简单方便。ClickHouse 核心开发人员在解决问题、合并和维护我们的 PR 到 ClickHouse 上提供了很大的帮助。例如,Cloudflare 的工程师贡献了大量代码到原仓库:
- 聚合函数 topK,贡献者:Marek Vavruša
- IP 前缀字典,贡献者:Marek Vavruša
- SummingMergeTree 引擎优化,贡献者:Marek Vavruša
- Kafka 表引擎,贡献者:Marek Vavruša。我们正在考虑,当这个引擎足够稳定时,用它来替换 Kafka Go 消费者,直接从 Kafka 摄取到 ClickHouse。
- 聚合函数 sumMap ,贡献者:Alex Bocharov。如果没有这个函数,我们就无法构建新的 Zone Analytics API。
- Mark 缓存修复,贡献者:Alex Bocharov
- uniqHLL12 函数修复,贡献者:Alex Bocharov。其中,issue 的描述和修复很有趣。
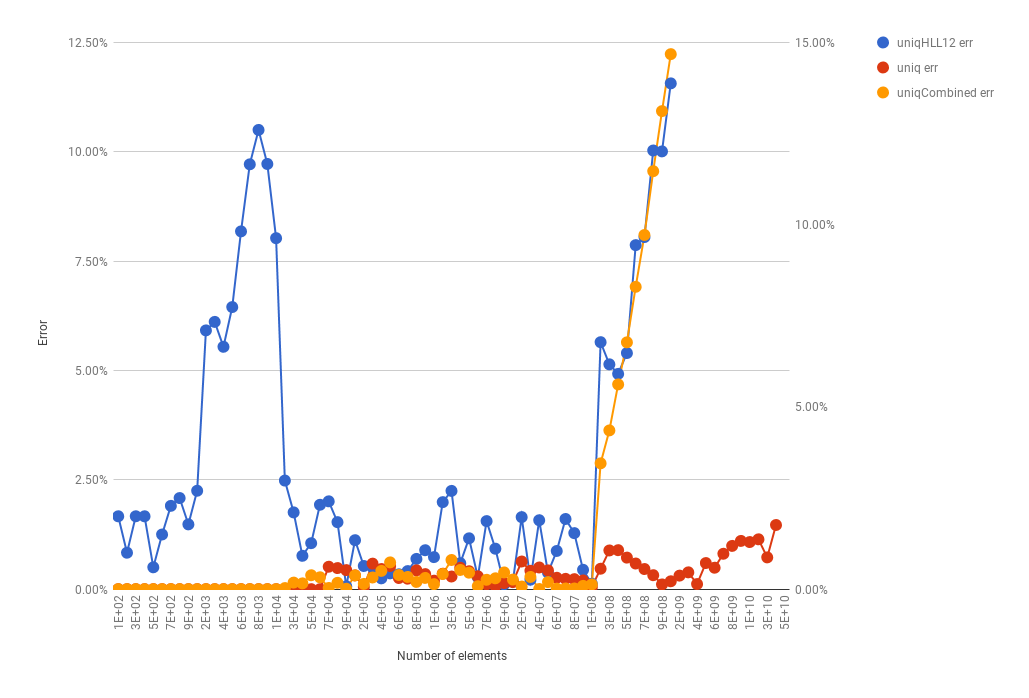
除了报告 bug,我们还报告我们集群中面对的每一个问题,我们希望这些问题将有助于改善 ClickHouse 。
尽管 ClickHouse 上的 DNS 分析已经取得了巨大的成功,但我们仍然怀疑我们是否能够将 ClickHouse 扩展到 HTTP 管道的需求:
- Kafka DNS 主题平均每秒有 150 万个消息,而 HTTP 请求主题每秒有 600 万个消息。
- Kafka DNS 主题的平均未压缩消息大小为 130B,而 HTTP 请求主题为 1630B。
- DNS 查询 ClickHouse 记录有 40 列, HTTP 请求 ClickHouse 记录有 104 列。
在尝试使用 Flink 不成功后,我们对 ClickHouse 能否跟上高摄取率表示怀疑。幸运的是,早期的原型显示出了可喜的性能,我们决定继续进行旧管道的替换。替换旧管道的第一步是为新的 ClickHouse 表设计一个结构。
ClickHouse 方案设计
一旦确定 ClickHouse 作为一个候选组件,我们便开始探索我们如何移植我们现有的 Postgres/Citus 模式,使它们与 ClickHouse 兼容。
对于我们的 Zone Analytics API,我们需要为每个区域(域)和时间段(每分钟/每小时/每天/每月)产生许多不同的聚合。要深入了解聚合的具体内容,请查看 Zone Analytics API 文档,或者这个现成的电子表格。
这些聚合应该在过去 365 天的任何时间范围内可用。虽然 ClickHouse 是一个非常伟大的工具,进行非聚合数据的工作,以及我们每秒的 600 万请求量,我们只是还不能承受存储非聚合数据那么久。
为了让大家了解数据量有多大,下面是一些 “餐巾纸数学” 的容量规划。我打算以平均每秒 600 百万的请求插入率和 100 美元作为 1TiB 的成本估算,计算不同消息格式下存储 1 年的成本。
| 消息格式 | Cap’n Proto | Cap’n Proto (zstd) | ClickHouse |
|---|---|---|---|
| 消息/记录的平均大小 | 1630 B | 360 B | 36.74 B |
| 存储1年的大小 | 273.93 PiB | 60.5 PiB | 18.52 PiB (RF x3) |
| 存储1年的花销 | $28M | $6.2M | $1.9M |
而这是我们假设每秒的请求量将保持不变,但事实上请求量一直在快速增长。
即使存储需求相当可怕,我们仍然考虑在 ClickHouse 中存储 1 个月以上的原始(非聚合)请求日志。参见下面的 “数据API的未来” 部分。
非聚合请求表
我们存储了 100 多个列,收集了每个通过 Cloudflare 的请求中很多不同类型的指标。其中一些列也可以在我们的企业日志共享(Enterprise Log Share)产品中使用,然而 ClickHouse 非聚合请求表的字段更多。
由于需要存储的列数太多,存储需求巨大,我们决定继续采用聚合数据的方式,这种方式在之前的旧管道中效果很好,而且可以为我们提供后向兼容性。
聚合模式设计 #1
根据 API 文档,我们需要提供很多不同的请求明细,为了满足这些要求,我们决定测试以下方法:
用 ReplicatedAggregatingMergeTree 引擎创建 Clickhouse 物化视图,指向非聚合请求表,并包含每个细分领域的微小聚合数据:
- 请求总数 - 包含总请求数、字节数、威胁数、独立访客量等指标。
- 按 colo 分类的请求 - 包含按 edgeColoId (Cloudflare的120多个数据中心中的标号)分类的请求、字节等
- 按 HTTP 状态的请求 - 包含按 HTTP 状态代码分类,如 200、404、500 等。
- 按内容类型划分的请求 - 包含按响应内容类型划分的请求,如 HTML、JS、CSS 等。
- 按国家分类的请求 - 包含按客户国家分类的请求(基于IP)。
- 按威胁类型划分的请求 - 包含按威胁类型划分的请求
- 按浏览器分类的请求** - 包含按浏览器系列分类的请求,从 User-Agent 中提取。
- 按 IP 类别划分的请求 - 包含按客户端 IP 类别划分的请求
使用两种方法,编写代码,从 8 个物化视图中收集数据:
- 使用 JOIN 一次查询 8 个物化视图
- 并行查询单独的 8 个物化视图
针对常见的 Zone Analytics API 查询运行基准性能测试

模式设计#1 没有很好的工作。ClickHouse JOIN 语法迫使写出超过 300 行的 SQL 畸形查询,重复多次选定的列,因为你只能在 ClickHouse 中进行配对连接。
至于并行查询每个单独的物化视图,基准测试的表现很好,结果显示查询吞吐量会比我们基于旧管道使用的 Citus 更好一点。
聚合模式设计 #2
在我们第二次迭代的模式设计中,我们努力保持与现有 Citus 表类似的结构。为此,我们尝试使用 SummingMergeTree 引擎,ClickHouse 超棒文档对其进行了详细的描述。
此外,一个表可以有嵌套的数据结构,这些嵌套的数据结构是以一种特殊的方式处理的。如果一个嵌套表的名称以 ‘Map’ 结尾,并且它至少包含两列符合以下标准的数据…那么这个嵌套表就被解释为 key =>(value…) 的映射,当合并它的行时,两个数据集的元素就会被 ‘key’ 与对应的 (value…) 相加合并。
对于发现的这个功能,我们感到高兴,因为与我们最初的方法相比,SummingMergeTree 引擎让我们大大减少了所需表的数量。同时,它也让我们能够匹配现有 Citus 表的结构。原因是以 ‘Map’ 结尾的 ClickHouse 嵌套结构与我们在旧管道中广泛使用的Postgres hstore 数据类型相似。
然而,ClickHouse 映射存在两个问题:
- SummingMergeTree 对所有具有相同主键的记录进行聚合,但所有分片的最终聚合应该使用聚合函数来完成,这在 ClickHouse 中并不存在。
- 对于存储唯一值(基于 IP 的 唯一访问者),我们需要使用 AggregateFunction 数据类型,虽然 SummingMergeTree 允许你用这样的数据类型创建列,但它不会对具有相同主键的记录进行聚合。
为了解决问题 #1,我们不得不创建一个新的聚合函数 sumMap 。幸运的是,ClickHouse 的源码质量很好,他们的核心开发人员对审阅代码和合并修改非常积极。
至于问题 #2,我们不得不把唯一值放到单独的物化视图中,使用 ReplicatedAggregatingMergeTree 引擎,并支持合并具有相同主键记录的 AggregateFunction 状态。我们正在考虑将同样的功能加入到 SummingMergeTree 中,这样会更加简化我们的设计模式。
我们还为 Colo 端点创建了一个单独的物化视图,因为它的使用率要低得多( Colo 端点查询的使用率为 5%,Zone 面板查询的使用率为 95% ),所以它比较分散的主键不会影响 Zone 面板查询的性能。
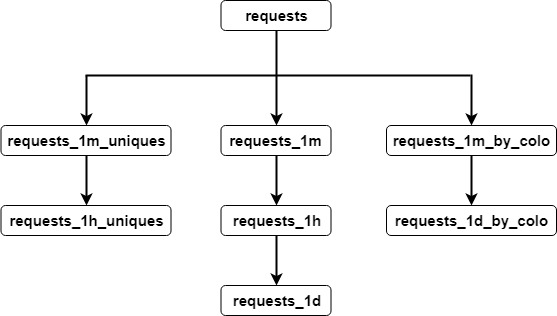
一旦设计模式通过,我们就开始进行性能测试。
ClickHouse 性能调节
我们探索了许多提高 ClickHouse 性能的途径。其中包括调整索引粒度,以及提高 SummingMergeTree 引擎的合并性能。
默认情况下,ClickHouse 建议使用 8192 索引粒度。有很好的文章深入解释 ClickHouse 主键和索引粒度。
虽然默认的索引粒度对于大多数用例来说可能是很好的选择,但在我们的案例中,我们决定选择以下索引粒度。
对于主要的非聚合请求表,我们选择了 16384 的索引粒度。对于这个表来说,查询中读取的行数通常在百万到数十亿的数量级。在这种情况下,较大的索引粒度不会对查询性能产生巨大的影响。
对于聚合静态的 requests_* ,我们选择了 32 的索引粒度。当我们只需要扫描和返回几条记录时,低索引粒度是有意义的。它在 API 性能上产生了巨大的变化 - 当我们改变索引粒度 8192 → 32 时,查询延迟降低了 50%,吞吐量增加了约 3 倍。
虽然与性能无关,但我们也禁用了 min_execution_speed 的设置,所以只扫描几行的查询不会因为每秒扫描行数的 “慢速” 而返回异常。
在聚合/合并方面,我们也做了一些 ClickHouse 的优化,比如把 SummingMergeTree 地图的合并速度提高了x7倍,我们把这些优化贡献回了 ClickHouse,为大家造福。
一旦我们完成了对 ClickHouse 的性能调优,我们就可以将其整合到一个新的数据管道中。接下来,我们将描述我们全新的、基于 ClickHouse 的数据管道架构。
全新的数据管道
新的数据管道架构重新使用了之前管道中的一些组件,然而我们替换了其中最薄弱的组件。
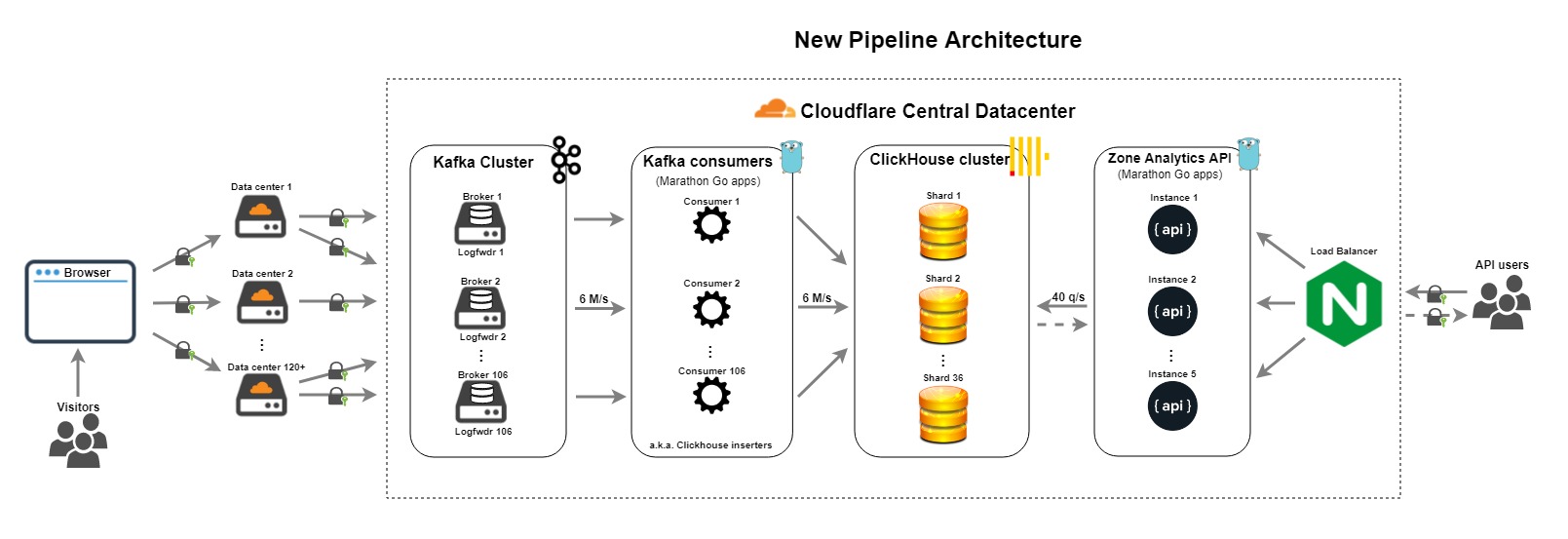
新的组件包括:
- Kafka 消费者 - 每个分区 106 个 Go 消费者消耗 Cap’n Proto 原始日志,并提取/准备需要的 100 多个 ClickHouse 字段。消费者不再做任何聚合逻辑。
- ClickHouse 集群 - 36 个节点,3个复制副本,处理非聚合请求日志摄取,然后使用物化视图产生聚合数据。
- Zone Analytics API - 重写并优化了使用 Go 编写的 API 版本,附带有意义的指标、健康检查、故障转移方案。
正如你所看到的,新管道的架构更加简单和容错。它为我们超过 7 百万客户的域提供分析,每月独立访问总量超过 25 亿,每月页面浏览量超过 1.5 万亿。
我们平均每秒处理 600 万个 HTTP 请求,最高峰时可达到每秒 800 万请求。
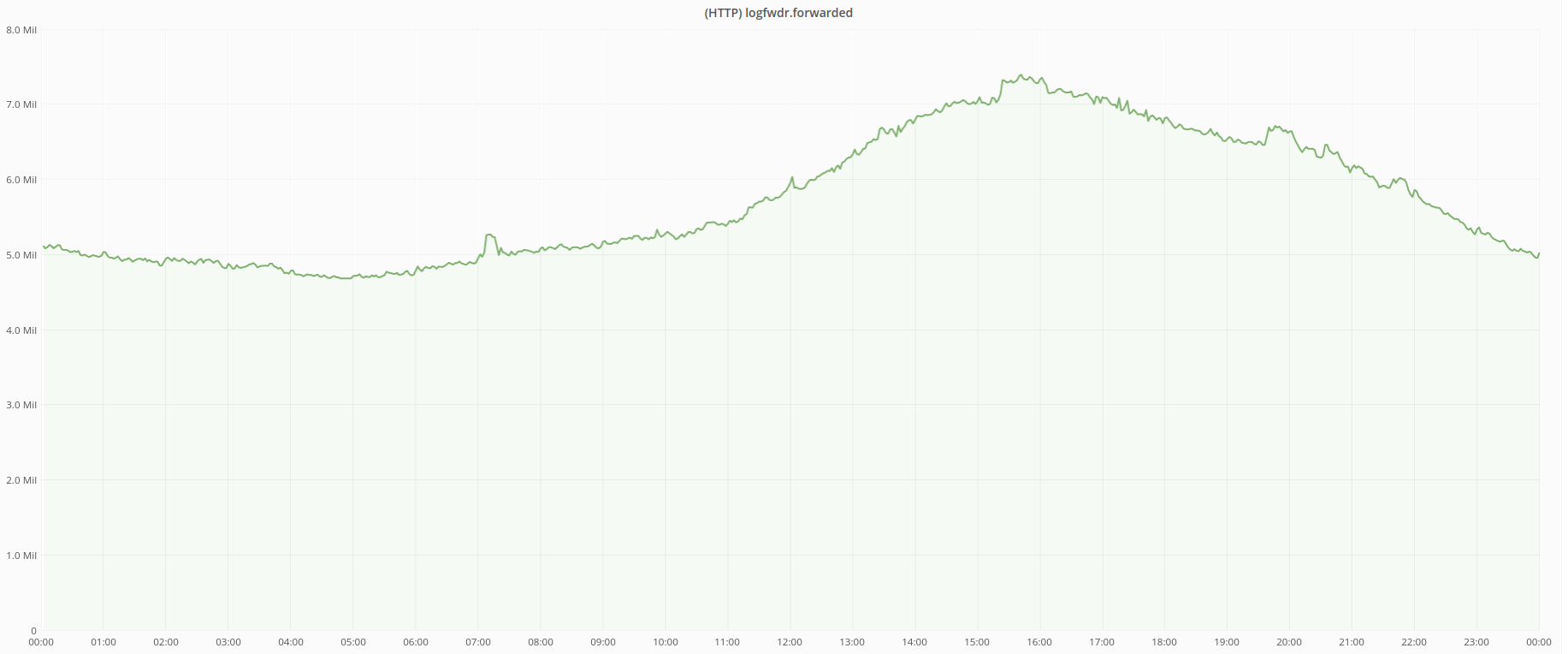
Cap’n Proto 格式的日志消息平均大小曾经是~1630B,但由于我们的平台运营团队在 Kafka 压缩方面做了惊人的工作,它显著减少了。请参阅 “挤压 firehose:从 Kafka 压缩中获得最大收益”博客文章,深入了解这些优化。
新管道的优点
无 SPOF(单点故障) - 去掉了所有的 SPOF 和瓶颈,所有组件的副本数量至少是3个。
容错 - 更加容错,即使 Kafka 消费者或 ClickHouse 节点或 Zone Analytics API 实例发生故障,也不会影响服务。
可扩展 - 我们可以添加更多的 Kafka broker 或 ClickHouse 节点,并随着我们的增长而扩展摄取量。当集群将增长到数百个节点时,我们对查询性能没抱有很大的信心。然而,Yandex 团队成功地将他们的集群扩展到 500 多个节点,在地理上分布在几个数据中心之间,使用两级分片。
降低了复杂性 - 由于去掉了乱七八糟的聚合定时任务和消费者,并且我们重构 API 代码,这使我们能够:
- 关闭 Postgres RollupDB 实例,并将其释放出来以供重用。
- 关闭 Citus 集群的 12 个节点,并将其释放出来供重用。由于我们不会再使用Citus 来处理严重的工作负载,我们可以减少运营和支持成本。
- 删除数万行旧的 Go、SQL、Bash 和 PHP 代码。
- 去掉 WWW PHP API 的依赖性和额外的延迟。
改善了 API 的吞吐量和延迟 - 使用以前的管道,Zone Analytics API 难以满足每秒超过 15 次的查询,因此我们不得不为大客户引入临时的强制速率限制。有了新的管道,我们能够去掉强制速率限制,现在我们的服务处理每秒约 40 个查询。我们进一步为新的 API 做了密集的负载测试,以目前的设置和硬件,我们能够提供每秒约 150 个查询,并且可以通过增加节点进行扩展。
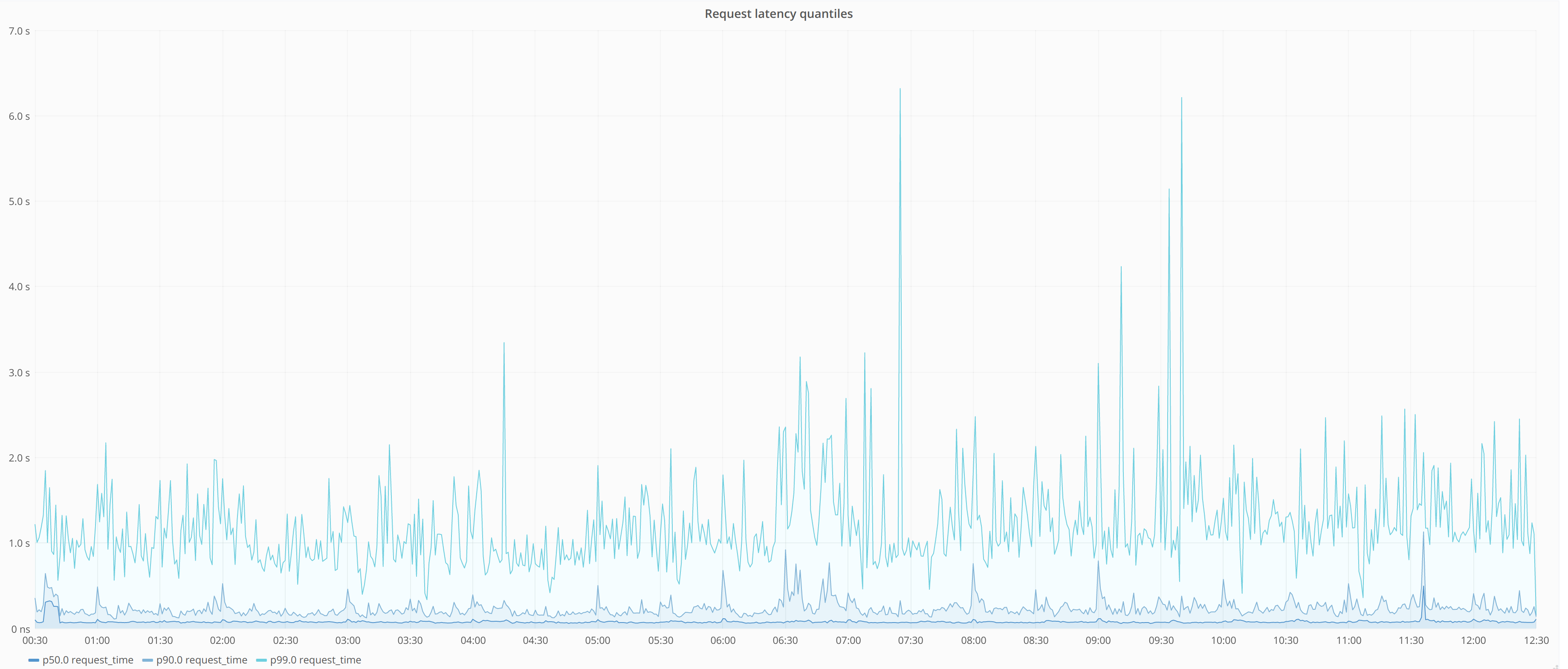
更容易维护 - 关闭了很多不可靠的组件,我们现在终于可以比较方便的维护这个管道。在这件事情上,ClickHouse 功不可没。
减少事故数量 - 有了新的更可靠的管道,我们现在的事故数量比以前少了,最终减少了 on-call 的负担。最后,我们可以在晚上安然入睡:-)。
最近,我们通过更好的硬件进一步提高了新管道的吞吐量和延迟。下面我会提供这个集群的细节。
我们的 ClickHouse 集群
我们总共有 36 个 ClickHouse 节点。新的硬件对我们来说是一个很大的提升:
- Chassis - 广达 D51B-2U 机箱升级为广达 D51PH-1ULH 机箱 (减少2倍的物理空间)
- CPU - 32 个核心的 E5-2630 v4 @ 2.20 GHz 升级为 40 个逻辑核心的 E5-2630 v3 @ 2.40 GHz
- 内存 - 128 GB 内存升级到 256 GB 内存
- 硬盘 - 12 x 6 TB 东芝 TOSHIBA MG04ACA600E 升级为 12 x 10 TB 希捷 ST10000NM0016-1TT101
- 网络 - 2 x 10G Intel 82599ES 升级为 2 x 25G Mellanox ConnectX-4 in MC-LAG
我们的平台运营团队发现,ClickHouse 还不擅长运行异构集群,所以我们需要逐步将现有集群中的全部 36 节点更换为全新的硬件。这个过程相当简单,跟更换故障节点没什么区别。问题是 ClickHouse 无法 throttle recovery。
下面是关于我们集群的更多信息:
- 平均插入速率 - 我们所有的管道每秒汇集 1100 万行。
- 平均插入带宽 - 47 Gbps。
- 平均每秒查询次数 - 集群平均每秒处理约 40 次查询,高峰期经常达到约 80 次查询。
- CPU时间 - 经过最近的硬件升级和所有优化,我们的集群 CPU 时间相当低。
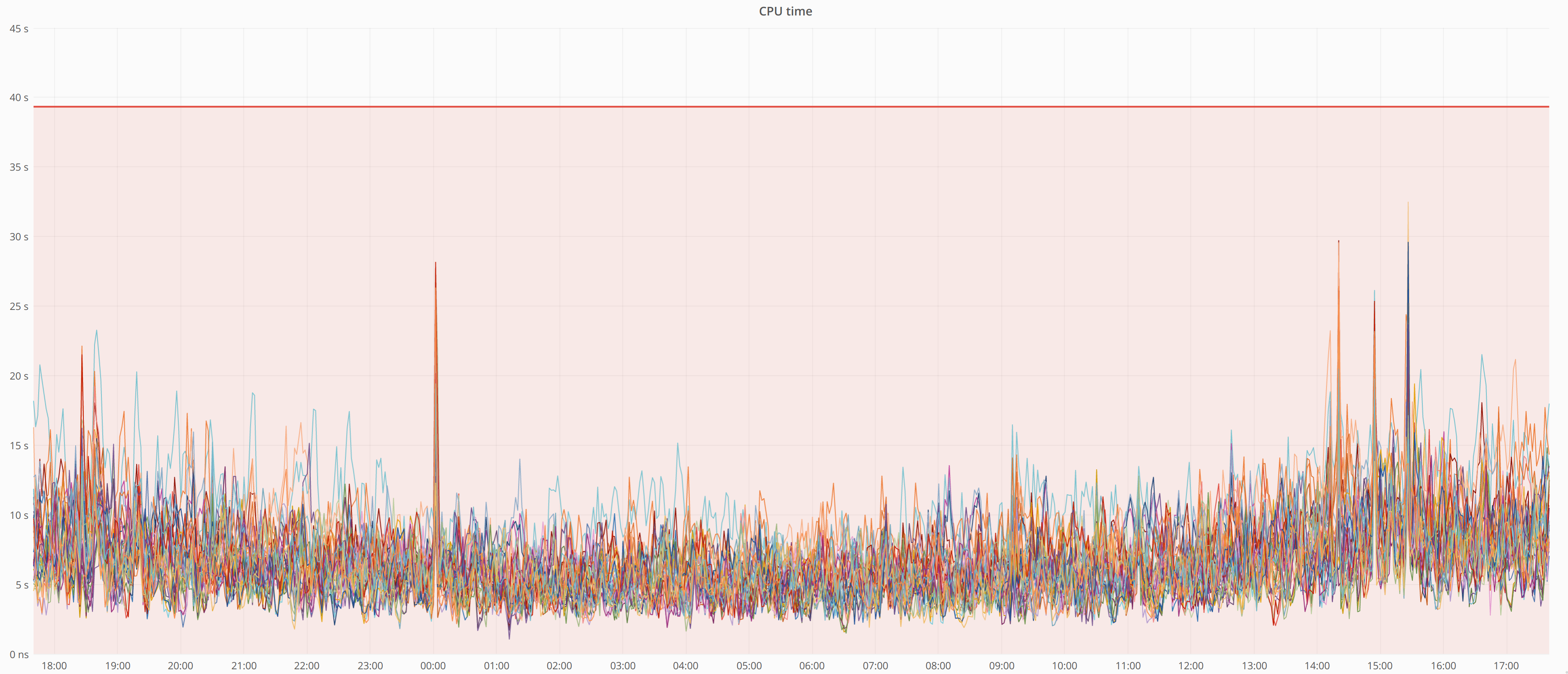
- 最大磁盘IO(设备时间) - 也很低。
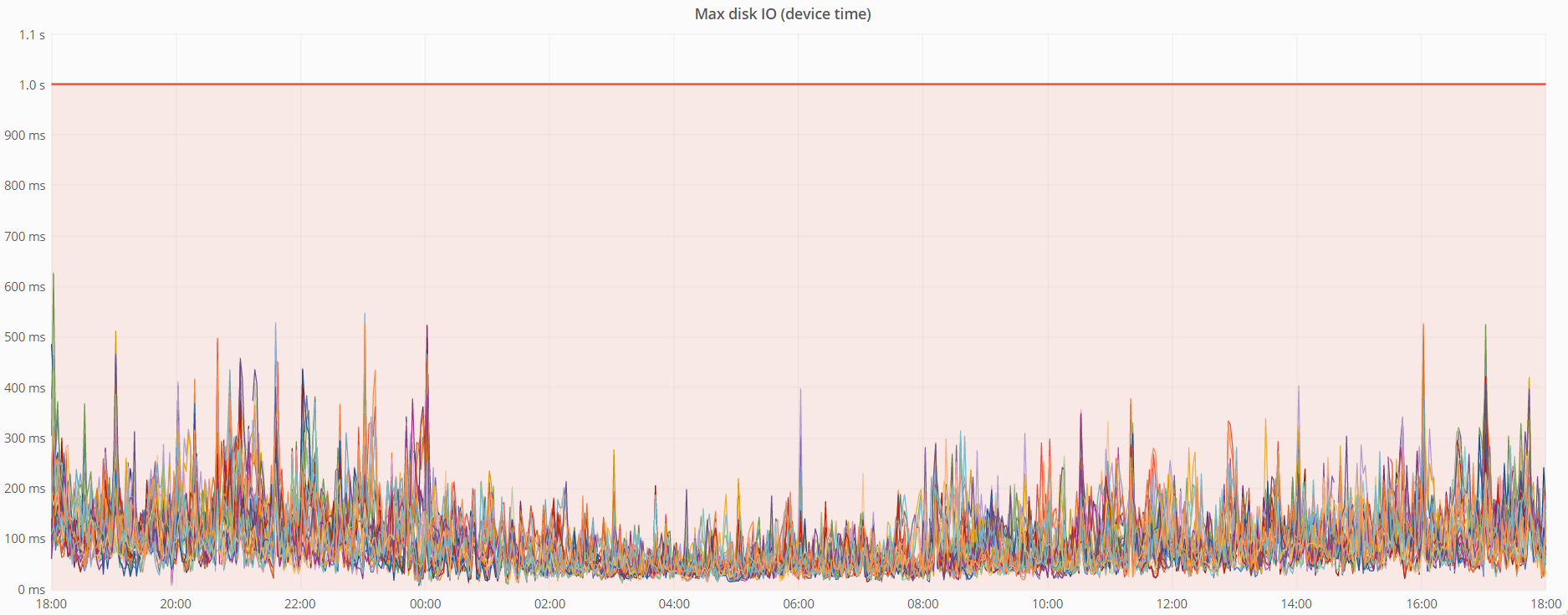
为了尽可能无缝地切换到新的管道,我们对旧管道的历史数据进行了转移。接下来,我将讨论这次数据转移的过程。
历史数据传输
由于我们有存储 1 年数据的需求,我们不得不在旧的 Citus 集群中做一个一次性 ETL(Extract Transfer Load)到 ClickHouse。
在 Cloudflare,我们喜欢 Go 以及 Go 的 goroutines ,所以直接地写了一个简单的 ETL 作业,如下:
- 每分钟/小时/日/月从 Citus 集群中提取数据。
- 将 Citus 数据转换为 ClickHouse 格式,并应用所需的业务逻辑。
- 将数据加载到 ClickHouse 中
整个过程花了几天时间,通过一致性检查,成功传输了 600 多亿行数据。这个过程的完成后,我们就关闭了旧管道。然而,我们的工作并没有结束,我们还在不断展望未来。在下一节中,我将分享一些我们正在规划的细节。
Data API 的未来
Log Push
我们目前正在研究一种叫做 “日志推送(Log Push)” 的东西。日志推送允许你指定一个所需的数据端点,并将你的 HTTP 请求日志自动定期发送到那里。目前,它还处于内部测试阶段,将支持把日志发送到以下目的地:
- Amazon S3 存储和桶
- Google 云服务的存储桶
- 其他存储平台或者服务
预计很快就会上市,但如果您对这款新产品感兴趣,想要试用,请联系我们的客户支持团队。
Logs SQL API
我们还在评估是否有可能开发名为 “日志 SQL API” 的新产品。我们的想法是通过灵活的 API 为客户提供访问他们日志的机会,支持标准的 SQL 语法和 JSON/CSV/TSV/XML 格式的响应。
查询可以提取。
- 请求日志的原始字段 (例如:SELECT field1, field2, … FROM requests WHERE …)
- 从请求日志中提取汇总数据 (例如:SELECT clientIPv4, count() FROM requests GROUP BY clientIPv4 ORDER BY count() DESC LIMIT 10)
谷歌 BigQuery 提供了类似的 SQL API,亚马逊也有名为 Kinesis Data analytics 的产品,也支持SQL API。
我们正在探索的另一个选择是提供类似于 DNS 分析 API 的语法,并提供过滤条件和维度。
总结
如果没有多个团队的努力工作,这一切都不可能实现! 首先要感谢数据团队其他工程师为实现这一切所做的巨大努力。平台运营团队为这个项目做出了重大贡献,尤其是 Ivan Babrou 和 Daniel Dao。DNS 团队的 Marek Vavruša 的贡献也非常有帮助。